



I. Introduction▲
┬½┬ĀD├®sormais, pour apprendre le fran├¦ais, il faudra SAVOIR le fran├¦ais┬Ā!┬Ā┬╗ disait Coluche. De m├¬me, ce tutoriel s'adresse ├Ā tous ceux qui connaissent d├®j├Ā les rudiments d'un langage ├®volu├® tel que le BASIC, le FORTRAN, le C ou le PASCAL et qui souhaitent apprendre l'assembleur. Une connaissance m├¬me sommaire d'un de ces langages suffit┬Ā! Aucune connaissance en programmation syst├©me n'est requise┬Ā: le but de ce cours est justement d'en introduire les fondements.
Contrairement aux langages ├®volu├®s, l'assembleur, ou ┬½┬Ālangage d'assemblage┬Ā┬╗ est constitu├® d'instructions directement compr├®hensibles par le microprocesseur┬Ā: c'est ce qu'on appelle un langage de bas niveau. Il est donc intimement li├® au fonctionnement de la machine. C'est pourquoi il est relativement difficile ├Ā assimiler, en tout cas beaucoup plus que les langages de haut niveau.
Cela explique ├®galement pourquoi il existe au moins autant de langages d'assemblage que de mod├©les de microprocesseurs.
Avant d'apprendre l'assembleur INTEL 80x86, il est donc primordial de s'int├®resser ├Ā quelques notions de base concernant par exemple la m├®moire ou le microprocesseur. C'est l├Ā en effet que se trouvent les principales difficult├®s pour le d├®butant. Ne soyez pas rebut├® par l'abstraction des concepts pr├®sent├®s dans les premiers paragraphes┬Ā: il est normal que durant la lecture, beaucoup de choses ne soient pas claires dans votre esprit. Tout vous semblera beaucoup plus simple quand nous passerons ├Ā la pratique dans le langage assembleur.
Le microprocesseur peut fonctionner sous deux modes┬Ā: le mode r├®el et le mode prot├®g├®. Le mode prot├®g├® permet d'acc├®der ├Ā 2^32 octets de m├®moire vive, alors que le mode r├®el ne peut en adresser que 2^20┬Ā=┬Ā1 Mo. Nous ne traiterons dans ce cours que le mode r├®el. C'est celui qu'utilisent la plupart des programmes DOS.
Convention┬Ā: toutes les adresses sont ├®crites en notation hexad├®cimale. Les autres nombres seront la plupart du temps repr├®sent├®s en base d├®cimale. Dans le cas contraire, nous ajouterons la lettre ŌĆśh' apr├©s les chiffres.
II. PREMI├łRE PARTIE▲
II-A. L'ARITHM├ēTIQUE SIGN├ēE▲
On appelle arithm├®tique non sign├®e l'arithm├®tique dans laquelle tous les entiers sont positifs. En arithm├®tique sign├®e au contraire, les nombres peuvent ├¬tre soit positifs, soit n├®gatifs. Un nombre sign├® n'est donc pas forc├®ment n├®gatif.
Les donn├®es informatiques se pr├®sentent sous la forme d'une succession de chiffres binaires, les bits. Nous supposerons que les syst├©mes de num├®ration binaire et hexad├®cimal vous sont d├®j├Ā familiers.
Il est en revanche fort possible que vous ne connaissiez pas la fa├¦on dont un ordinateur repr├®sente les nombres n├®gatifs. Il existe deux conventions┬Ā: la notation en signe et valeur absolue et la notation en compl├®ment ├Ā 2.
La premi├©re est extr├¬mement simple┬Ā: le premier bit repr├®sente le signe, et les autres bits la valeur absolue du nombre. Le bit de signe vaut 1 si le nombre est strictement n├®gatif, 0 sinon.
Par exemple, le nombre (-14) cod├® sur 8 bits s'├®crit ainsi┬Ā:
10001110
Cette convention n'est quasiment jamais utilis├®e en informatique. On lui pr├®f├©re la repr├®sentation en compl├®ment ├Ā 2 dont le principe est le suivant┬Ā:
- les nombres positifs sont cod├®s de la m├¬me fa├¦on qu'en convention ┬½┬Āsigne et valeur absolue┬Ā┬╗┬Ā;
- les nombres n├®gatifs sont obtenus en inversant tous les bits, puis en ajoutant 1.
Exemple┬Ā: le nombre 14 cod├® sur 8 bits est repr├®sent├® ainsi┬Ā:
00001110
et (-14) ainsi┬Ā:
- inversion des bits┬Ā: 11110001┬Ā;
- ajout d'une unit├®┬Ā: 11110010┬Ā;
- r├®sultat┬Ā: 11110010.
Remarque┬Ā: le r├®sultat interm├®diaire, 11110001, est appel├® ┬½┬Ācompl├®ment ├Ā 1┬Ā┬╗.
Vous allez imm├®diatement comprendre l'avantage de cette repr├®sentation. Faisons la somme de 14 et de (-14), de la m├¬me fa├¦on que s'il s'agissait d'entiers positifs┬Ā:
00001110 + 11110010┬Ā=┬Ā100000000
Le r├®sultat ├®tant cod├® sur 8 bits, le 1 situ├® ├Ā gauche n'est pas pris en compte. On obtient donc 14 + (-14)┬Ā=┬Ā0.
L'int├®r├¬t ├®vident est que la diff├®rence de deux nombres peut se calculer avec le m├¬me algorithme que leur somme. Il suffit de transformer au pr├®alable le nombre retranch├® en son oppos├®. Cette conversion est tr├©s simple et tr├©s rapide.
Au contraire, en repr├®sentation ┬½┬Āsigne et valeur absolue┬Ā┬╗, on aurait eu besoin de nombreux algorithmes, car plusieurs cas se pr├®sentent.
Remarque┬Ā: la repr├®sentation en compl├®ment ├Ā 2 revient en fait ├Ā ├®crire (-1) comme ceci┬Ā:
11111111
(-2) comme cela┬Ā:
11111110
(-3) comme cela┬Ā:
11111101
etc.
Il y a ainsi une sym├®trie entre les nombres positifs et les nombres n├®gatifs. Il en r├®sulte que le bit le plus ├Ā gauche repr├®sente le signe, de la m├¬me fa├¦on qu'en notation ┬½┬Āsigne et valeur absolue┬Ā┬╗. Avant tout calcul, nous pouvons donc affirmer que le nombre 10010101 est n├®gatif.
II-B. LA M├ēMOIRE VIVE▲
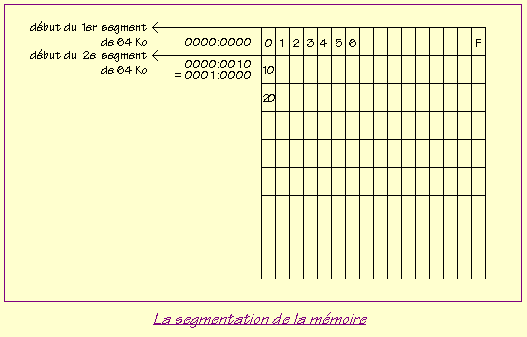
II-B-1. La segmentation de la m├®moire▲
Votre PC est con├¦u pour g├®rer 1 Mo (soit 220 octets) de m├®moire vive en mode r├®el. Il faut donc 20 bits au minimum pour adresser toute la m├®moire. Or en mode r├®el les bus d'adresses n'ont que 16 bits. Ils permettent donc d'adresser 216┬Ā=┬Ā65536 octets┬Ā=┬Ā64 Ko, ce qui est insuffisant┬Ā!
Afin de pallier ce manque, on utilise deux nombres pour adresser un octet quelconque de la RAM. Le premier est appel├® adresse de segment, le second adresse d'offset. Ils seront stock├®s s├®par├®ment.
La m├®moire est d├®coup├®e en segments de 64 Ko chacun. Un segment est donc en quelque sorte un gros bloc de m├®moire auquel on peut acc├®der gr├óce ├Ā une adresse de segment qui d├®signe son num├®ro. Par exemple, le premier segment est le segment 0000 (en hexa), le deuxi├©me est le 0001, le quarante-deuxi├©me est le 0029, etc. Chaque num├®ro est cod├® sur 16 bits, c'est-├Ā-dire 4 chiffres hexa.
Pour acc├®der ├Ā un octet particulier dans un segment, il suffit de compter le d├®calage de cet octet par rapport au d├®but du segment. Ce d├®calage est obligatoirement inf├®rieur ou ├®gal ├Ā 65535┬Ā: il tient bien sur 16 bits lui aussi. On appelle ce d├®calage ┬½┬Āoffset┬Ā┬╗.
L'adresse d'un octet se note XXXX:YYYY o├╣ XXXX est l'adresse de segment et YYYY est l'offset (tous deux en notation hexad├®cimale, bien s├╗r).
Par exemple, le dix-septi├©me octet de la RAM (le num├®ro 16) est situ├® ├Ā l'adresse 0000:0010. De m├¬me, l'octet 0000:0100 est l'octet num├®ro 256. Nous en arrivons ├Ā la petite subtilit├® qu'il convient de bien saisir, sous peine de ne rien comprendre ├Ā certains programmes en assembleur.
On pourrait penser que l'octet qui se trouve ├Ā l'adresse 0001:0000 est le num├®ro 65536. Il n'en est rien. C'est l'octet num├®ro 16.
Eh oui┬Ā! Les segments ne sont pas situ├®s gentiment les uns ├Ā la suite des autres. Ils sont fort mal ├®lev├®s et n'attendent pas que les segments qui les pr├®c├©dent soient termin├®s avant de commencer┬Ā! Ils se marchent donc sur les pieds.
Autrement dit, le deuxi├©me segment ne d├®marre pas ├Ā l'octet 65536 comme il devrait le faire s'il ├®tait bien sage, mais ├Ā l'octet 16┬Ā! Le troisi├©me d├®marre ├Ā l'octet 32 et ainsi de suiteŌĆ”
La notion de segment n'est pas tant physique que math├®matique┬Ā: elle sert ├Ā se rep├®rer dans la RAM.
La cons├®quence imm├®diate de tout cela est qu'un octet n'a pas une adresse unique. Par exemple, l'octet num├®ro 66 peut ├¬tre adress├® par 0000:0042, mais aussi par 0001:0032, par 0002:0022, par 0003:0012 ou encore par 0004:0002. Toutes ces adresses sont ├®quivalentes.
Voil├Ā pour la subtilit├®. Si vous avez compris, vous devriez ├¬tre capable de trouver facilement comment on calcule l'adresse effective d'un octet, c'est-├Ā-dire sa position absolue dans la RAM.
Allez, un petit effort┬Ā!
Voici la solution┬Ā: si l'adresse de l'octet est A17C:022E, alors son adresse effective est A17C x 16 + 022E, soit A17C0 + 022E┬Ā=┬ĀA19EE. On a multipli├® par 16, car le segment A17C d├®bute ├Ā l'octet A17C x 16, puis on a simplement ajout├® le d├®calage.
Au final, on a bien une adresse sur 20 bits puisqu'on obtient 5 chiffres hexa. Chaque petit bloc de 16 octets s'appelle un paragraphe.
Il est souvent plus simple de consid├®rer qu'un segment est un bloc de taille quelconque qui d├®bute ├Ā une adresse effective multiple de 16 et qui permet, ├Ā l'aide de son adresse de segment et d'un offset, d'adresser le bloc entier (64 Ko au maximum). Cette d├®finition est ├Ā notre avis celle qui a le plus de sens, et nous l'utiliserons tout au long de ce cours.
II-B-2. Structure d'un programme en m├®moire▲
Lorsque l'utilisateur ex├®cute un programme, celui-ci est d'abord charg├® en m├®moire par le syst├©me. Le DOS distingue deux mod├©les de programmes ex├®cutables┬Ā: les fichiers COM et les fichiers EXE.
La diff├®rence fondamentale est que les programmes COM ne peuvent pas utiliser plus d'un segment dans la m├®moire. Leur taille est ainsi limit├®e ├Ā 64 Ko. Les programmes EXE ne sont quant ├Ā eux limit├®s que par la m├®moire disponible dans l'ordinateur.
II-B-3. Les fichiers COM▲
Lorsqu'il charge un fichier COM, le DOS lui alloue toute la m├®moire disponible. Si celle-ci est insuffisante, il le signale ├Ā l'utilisateur par un message et annule toute la proc├®dure d'ex├®cution. Dans le cas contraire, il cr├®e le PSP du programme au d├®but du bloc de m├®moire r├®serv├®, et copie le programme ├Ā charger ├Ā la suite.
Mais qu'est-ce donc qu'un PSP┬Ā?
Pour simplifier, le PSP (┬½┬ĀProgram Segment Prefix┬Ā┬╗) est une zone de 256 (= 100h) octets qui contient des informations diverses au sujet du programme. C'est dans le PSP que se trouve la ligne de commande tap├®e par l'utilisateur. Par exemple, le PSP d'un programme appel├® MONPROG, ex├®cut├® avec la commande ┬½┬ĀMONPROG monfic.txt /S /H┬Ā┬╗, contiendra la cha├«ne de caract├©res suivante┬Ā: ┬½┬Āmonfic.txt /S /H┬Ā┬╗. Le programmeur a ainsi la possibilit├® d'acc├®der aux param├©tres.
Voici ├Ā titre indicatif la structure simplifi├®e du PSP (ne vous souciez pas de ce que vous ne comprenez pas┬Ā: pour l'instant, seules les deux derni├©res lignes nous int├®ressent vraiment)┬Ā:
| Offset | Description | Taille (octets) |
| 00 h | Appel de l'int 20h | 2 |
| 02 h | Adresse du 1er segment qui se trouve au-del├Ā du prog. | 2 |
| 04 h | R├®serv├® | 1 |
| 05 h | Far call de l'int 21h (inutilis├®) | 5 |
| 0A h | Vecteur de l'int 22h | 4 |
| 0E h | Vecteur de l'int 23h | 4 |
| 12 h | Vecteur de l'int 24h | 4 |
| 16 h | R├®serv├® | 22 |
| 2C h | Segment du bloc d'environnement | 2 |
| 2E h | R├®serv├® | 82 |
| 80 h | Nombre de caract├©res dans la ligne de commande sans compter le code ASCII 13 (retour chariot) | 1 |
| 81 h | Ligne de commande (├Ā partir du caract├©re espace qui suit le nom du programme) + code ASCII 13 | 127 |
├Ć pr├®sent que nous connaissons l'existence du PSP, il nous faut revenir sur un point important. Comme nous l'avons dit, un programme COM ne peut comporter qu'un seul segment, bien que le DOS lui r├®serve la totalit├® de la m├®moire disponible. Ceci a deux cons├®quences. La premi├©re est que les adresses de segment sont inutiles dans le programme┬Ā: les offsets seuls permettent d'adresser n'importe quel octet du segment. La seconde est que le PSP fait partie de ce segment, ce qui limite ├Ā 64 Ko - 256 octets la taille maximale d'un fichier COM. Cela implique ├®galement que le programme lui-m├¬me d├®bute ├Ā l'offset 100h et non ├Ā l'offset 0h.
II-B-4. Les fichiers EXE▲
┬½┬ĀPour un fichier EXE, tout est toujours un peu plus compliqu├®.┬Ā┬╗
(Devise du programmeur d├®butant en assembleur)
Bien qu'il soit possible de n'utiliser qu'un seul segment ├Ā tout faire, la plupart des programmes EXE ont un segment r├®serv├® au code (c'est ainsi qu'on appelle les instructions du langage machine), un ou deux autres aux donn├®es, et un dernier ├Ā la pile.
La pile est une m├®moire tr├©s sp├®ciale qui sert comme son nom l'indique ├Ā empiler des donn├®es de 16 bits de fa├¦on temporaire. On peut ensuite retrouver ces donn├®es en les d├®pilant. Le ┬½┬Ād├®pilage┬Ā┬╗ se fait toujours dans l'ordre inverse de l'empilage.
Le PSP a lui aussi son propre segment. Le programme commence donc ├Ā l'offset 0h du segment de code et non ├Ā l'offset 100h.
Afin que le programme puisse ├¬tre charg├® et ex├®cut├® correctement, il faut que le syst├©me sache o├╣ commence et o├╣ s'arr├¬te chacun de ces segments. ├Ć cet effet, les compilateurs cr├®ent un en-t├¬te (ou ┬½┬Āheader┬Ā┬╗) au d├®but de chaque fichier EXE. Ce header ne sera pas copi├® en m├®moire. Son r├┤le est simplement d'indiquer au DOS (lors du chargement) la position relative de chaque segment dans le fichier.
II-B-5. Les cycles de lecture-├®criture▲
Le code et les variables d'un programme se trouvent dans la m├®moire vive. Pour acc├®der ├Ā une donn├®e en m├®moire, le processeur place son adresse dans un bus d'adresse. Un cycle de lecture se met alors en place. Il consiste ├Ā retourner la donn├®e lue au processeur via le bus de donn├®es.
Pour l'├®criture, l'adresse de la destination est transmise dans le bus d'adresse et la donn├®e ├Ā ├®crire est plac├®e dans le bus de donn├®es.
Ouf┬Ā!
Nous aurons l'occasion de revenir sur la m├®moire vive dans les autres chapitres pour apporter quelques pr├®cisions. Vous devriez mieux comprendre toutes ces notions en lisant la suite, car jusqu'ici nous n'avons pas encore parl├® de la fa├¦on dont l'ordinateur se sert des adresses pour acc├®der ├Ā des donn├®es ou pour ex├®cuter du code. C'est l├Ā qu'intervient le microprocesseurŌĆ”
II-C. LE MICROPROCESSEUR - LES REGISTRES▲
II-C-1. G├®n├®ralit├®s sur les registres▲
Le microprocesseur est le c┼ōur de l'ordinateur. C'est lui qui est charg├® de reconna├«tre les instructions et de les ex├®cuter (ou de les faire ex├®cuter). Chaque instruction se pr├®sente sous la forme d'une suite de bits qu'on repr├®sente en notation hexad├®cimale (exemple┬Ā: B44C, ou 1011010001001100 en binaire). Une instruction se compose d'un code op├®rateur (le plus souvent appel├® ┬½┬Āopcode┬Ā┬╗) qui d├®signe l'action ├Ā effectuer (B4 dans notre exemple) et d'un ┬½┬Āchamp d'op├®randes┬Ā┬╗ sur lesquels porte l'op├®ration (ici l'op├®rande est 4C).
Pour travailler, le microprocesseur utilise de petites zones o├╣ il peut stocker des donn├®es. Ces zones portent le nom de registres et sont tr├©s rapides d'acc├©s puisqu'elles sont implant├®es dans le microprocesseur lui-m├¬me et non dans la m├®moire vive.
Les registres des processeurs INTEL se classent en quatre cat├®gories┬Ā:
- les registres g├®n├®raux (16 bits)┬Ā;
- les registres de segment (16 bits)┬Ā;
- les registres d'offset (16 bits)┬Ā;
- le registre des indicateurs (16 bits).
II-C-2. Les registres g├®n├®raux▲
Ils ne sont pas r├®serv├®s ├Ā un usage tr├©s pr├®cis, aussi les utilise-t-on pour manipuler des donn├®es diverses. Ce sont en quelque sorte des registres ├Ā tout faire. Chacun de ces quatre registres peut servir pour la plupart des op├®rations, mais ils ont tous une fonction principale qui les caract├®rise.
| Nom | Fonction privil├®gi├®e |
| AX | Accumulateur |
| BX | Base |
| CX | Compteur |
| DX | Donn├®es |
Le registre AX sert souvent de registre d'entr├®e-sortie┬Ā: on lui donne des param├©tres avant d'appeler une fonction ou une proc├®dure. Il est ├®galement utilis├® pour de nombreuses op├®rations arithm├®tiques, telles que la multiplication ou la division de nombres entiers. Il est appel├® ┬½┬Āaccumulateur┬Ā┬╗.
Exemples d'utilisation┬Ā:
- l'instruction ŌĆ£MOV AX, 1982ŌĆØ place l'entier 1982 dans AX┬Ā;
- ŌĆ£ADD AX, 1983ŌĆØ ajoute ├Ā AX le nombre 1983 et place le r├®sultat dans AX.
Le registre BX peut servir de base. Nous verrons plus tard ce que ce terme signifie.
Le registre CX est utilis├® comme compteur dans les boucles. Par exemple, pour r├®p├®ter 15 fois une instruction en assembleur, on peut mettre la valeur 15 dans CX, ├®crire l'instruction pr├®c├®d├®e d'une ├®tiquette qui repr├®sente son adresse en m├®moire, puis faire un LOOP ├Ā cette adresse. Lorsqu'il reconna├«t l'instruction LOOP, le processeur ┬½┬Āsait┬Ā┬╗ que le nombre d'it├®rations ├Ā ex├®cuter se trouve dans CX. Il se contente alors de d├®cr├®menter CX, de v├®rifier que CX est diff├®rent de 0 puis de faire un saut (┬½┬Ājump┬Ā┬╗) ├Ā l'├®tiquette mentionn├®e. Si CX vaut 0, le processeur ne fait pas de saut et passe ├Ā l'instruction suivante.
Exemple┬Ā:

Le registre DX contient souvent l'adresse d'un tampon de donn├®es lorsqu'on appelle une fonction du DOS. Par exemple, pour ├®crire une cha├«ne de caract├©res ├Ā l'├®cran, il faut placer l'offset de cette cha├«ne dans DX avant d'appeler la fonction appropri├®e.
Chacun de ces quatre registres comporte 16 bits. On peut donc y stocker des nombres allant de 0 ├Ā 65535 en arithm├®tique non sign├®e, et des nombres allant de -32768 ├Ā 32767 en arithm├®tique sign├®e. Les 8 bits de poids fort d'un registre sont appel├®s ┬½┬Āpartie haute┬Ā┬╗ et les 8 autres ┬½┬Āpartie basse┬Ā┬╗. Chaque registre est en fait constitu├® de deux ┬½┬Āsous-registres┬Ā┬╗ de 8 bits. La partie haute de AX s'appelle AH, sa partie basse AL. Il en va de m├¬me pour les trois autres.
En arithm├®tique non sign├®e, il en d├®coule la formule suivante┬Ā:
AX┬Ā=┬ĀAH x 256 + AL
ainsi que leurs homologues┬Ā:
BX┬Ā=┬ĀBH x 256 + BL
CX┬Ā=┬ĀCH x 256 + CL
DX┬Ā=┬ĀDH x 256 + DL
Il va de soi qu'en modifiant AL ou AH, on modifie ├®galement AX.
Pour stocker un nombre de 32 bits, on peut utiliser des paires de registres. Par exemple, DX:AX signifie DX x 65535 + AX en arithm├®tique non sign├®e.
Cette notation (DX:AX) n'est pas reconnue par l'assembleur (ni par la machine). Ne confondez pas cela avec les adresses de segment et d'offset.
Sur un PC relativement r├®cent, AX, BX, CX, DX ne sont en fait que les parties basses de registres de 32 bits nomm├®s EAX, EBX, ECX, EDX (┬½┬ĀE┬Ā┬╗ pour ┬½┬ĀExtended┬Ā┬╗). On a donc un moyen plus pratique de stocker les grands nombres. En fait, chaque registre (pas seulement les registres g├®n├®raux) peut contenir 32 bits.
II-C-3. Les registres de segment▲
Ils sont au nombre de quatre┬Ā:
| Nom | Nom complet | Traduction |
| CS | Code segment | Segment de code |
| DS | Data segment | Segment de donn├®es |
| ES | Extra segment | Extra segment |
| SS | Stack segment | Segment de pile |
Contrairement aux registres g├®n├®raux, ces registres ne peuvent servir pour les op├®rations courantes┬Ā: ils ont un r├┤le tr├©s pr├®cis. On ne peut d'ailleurs pas les utiliser aussi facilement que AX ou BX, et une petite modification de l'un d'eux peut suffire ├Ā ┬½┬Āplanter┬Ā┬╗ le syst├©me. Eh oui┬Ā! L'assembleur, ce n'est pas Turbo Pascal┬Ā! Il n'y a aucune barri├©re de protection, si bien qu'une petite erreur peut planter le DOS. Mais rassurez-vous┬Ā: tout se r├®pare tr├©s bien en red├®marrant l'ordinateurŌĆ”
Dans le registre CS est stock├®e l'adresse de segment de la prochaine instruction ├Ā ex├®cuter. La raison pour laquelle il ne faut surtout pas changer sa valeur directement est ├®vidente. De toute fa├¦on, vous ne le pouvez pas. Le seul moyen viable de le faire est d'utiliser des instructions telles que des sauts (JMP) ou des appels (CALL) vers un autre segment. CS sera alors automatiquement actualis├® par le processeur en fonction de l'adresse d'arriv├®e.
Le registre DS est quant ├Ā lui destin├® ├Ā contenir l'adresse du segment des donn├®es du programme en cours. On peut le faire varier ├Ā condition de savoir exactement pourquoi on le fait. Par exemple, on peut avoir deux segments de donn├®es dans son programme et vouloir acc├®der au deuxi├©me. Il faudra alors faire pointer DS vers ce segment.
ES est un registre qui sert ├Ā adresser le segment de son choix. On peut le changer aux m├¬mes conditions que DS. Par exemple, si on veut copier des donn├®es d'un segment vers un autre, on pourra faire pointer DS vers le premier et ES vers le second.
Le registre SS adresse le segment de pile. Il est rare qu'on doive y toucher car le programme n'a qu'une seule pile.
Int├®ressons-nous ├Ā pr├®sent aux valeurs que le DOS donne ├Ā ces registres lors du chargement en m├®moire d'un fichier ex├®cutable┬Ā! Elles diff├©rent selon que le fichier est un programme COM ou EXE. Pour ├®crire un programme en assembleur, il est n├®cessaire de conna├«tre ce tableau par c┼ōur┬Ā:
| Registre | Valeur avant l'ex├®cution | |
| Fichier COM | Fichier EXE | |
| CS | Adresse de l'unique segment, c'est-├Ā-dire adresse de segment du PSP | Adresse du segment de code |
| DS | Adresse de l'unique segment, c'est-├Ā-dire adresse de segment du PSP | Adresse de segment du PSP |
| ES | Adresse de l'unique segment, c'est-├Ā-dire adresse de segment du PSP | Adresse de segment du PSP |
| SS | Adresse de l'unique segment, c'est-├Ā-dire adresse de segment du PSP | Adresse du segment de pile |
Le sch├®ma suivant montre mieux la situation┬Ā:

Dans un fichier EXE, le header indique au DOS les adresses initiales de chaque segment par rapport au d├®but du programme (puisque le compilateur n'a aucun moyen de conna├«tre l'adresse ├Ā laquelle le programme sera charg├®). Lors du chargement, le DOS ajoutera ├Ā ces valeurs l'adresse d'implantation pour obtenir ainsi les v├®ritables adresses de segment.
Dans le cas d'un fichier COM, tout est plus simple. Le programme ne comporte qu'un seul segment, donc il suffit tout bêtement au DOS de charger CS, DS, ES et SS avec l'adresse d'implantation.
Remarque┬Ā: Pourquoi DS et ES pointent-ils vers le PSP dans le cas d'un fichier EXE┬Ā? Premi├©re raison┬Ā: pour que le programmeur puisse acc├®der au PSP┬Ā! Deuxi├©me raison┬Ā: parce qu'un programme EXE peut comporter un nombre quelconque de segments de donn├®es. C'est donc au programmeur d'initialiser ces registres, s'il veut acc├®der ├Ā ses donn├®es.
II-C-4. Les registres d'offset▲
Les voici┬Ā:
| Nom | Nom complet | Traduction |
| IP | Instruction pointer | Pointeur d'instruction |
| SP | Stack pointer | Pointeur de pile |
| SI | Source index | Index de source |
| DI | Destination index | Index de destination |
| BP | Base pointer | Pointeur de base |
Le registre IP d├®signe l'offset de la prochaine instruction ├Ā ex├®cuter, par rapport au segment adress├® par CS. La combinaison de ces deux registres (i.e. CS:IP) suffit donc ├Ā conna├«tre l'adresse absolue de cette instruction. Le processeur peut alors aller la chercher en m├®moire et l'ex├®cuter. De plus, il actualise IP en l'incr├®mentant de la taille de l'instruction en octets. Tout comme CS, il est impossible de modifier IP directement.
Le registre SP d├®signe le sommet de la pile. Il faut bien comprendre le fonctionnement de la pile, aussi allons-nous insister sur ce point. La pile ne peut stocker que des mots. On appelle un mot (┬½┬Āword┬Ā┬╗ en anglais) un nombre cod├® sur deux octets (soit 16 bits). Prenons un exemple simple┬Ā: un programme COM. Le segment de pile (adress├® par SS) et le segment de code ne font qu'un. Avant l'ex├®cution, SP vaut FFFE. C'est l'offset de la derni├©re donn├®e de 16 bits empil├®e, par rapport ├Ā SS bien s├╗r. Pourquoi FFFE┬Ā? Tout simplement parce que la pile se remplit ├Ā l'envers, c'est-├Ā-dire en partant de la fin du segment et en remontant vers le d├®but. Le premier mot empil├® se trouve ├Ā l'offset FFFE. Il tient sur deux octets┬Ā: l'octet FFFE et l'octet FFFF. Mais comment se fait-il qu'un mot soit d├®j├Ā empil├® avant le d├®but du programme┬Ā? Ce mot est un z├®ro que le DOS place sur la pile avant l'ex├®cution de tout programme COM. Nous en verrons la raison plus tard.
├Ć pr├®sent, que se passe-t-il si ├Ā un instant quelconque une instruction ordonne au processeur d'empiler un mot ? Eh bien le stack pointer sera d├®cr├®ment├® de 2 et le mot sera copi├® ├Ā l'endroit point├® par SP. Rappelez-vous que la pile se remplit ├Ā l'envers┬Ā! C'est pour cette raison que SP est d├®cr├®ment├® ├Ā chaque empilage et non pas incr├®ment├®.
Un petit exemple pour rendre les choses plus concr├©tes┬Ā:
PUSH AX
L'effet de cette instruction est d'empiler le mot contenu dans le registre AX. Autrement dit, SP est automatiquement d├®cr├®ment├® de 2, puis AX est copi├® ├Ā l'adresse SS:SP.
Lors du d├®pilage, le mot situ├® au sommet de la pile, c'est-├Ā-dire le mot adress├® par SS:SP, est transf├®r├® dans un registre quelconque choisi par le programmeur, apr├©s quoi le stack pointer est incr├®ment├® de 2.
Exemple┬Ā:
POP BX
Cette fois, on retire le dernier mot empil├® pour le placer dans le registre BX. ├ēvidemment, SP sera incr├®ment├® de 2 aussit├┤t apr├©s.
La pile est extr├¬mement utile lorsqu'il s'agit de stocker provisoirement le contenu d'un registre qui doit ├¬tre modifi├®.
Exemple┬Ā:

Il est important de comprendre qu'on ne peut d├®piler que le mot qui se trouve au sommet de la pile. Le premier mot empil├® est le dernier qui sera d├®pil├®. La pile doit ├¬tre manipul├®e avec une extr├¬me pr├®caution. Un d├®pilage injustifi├® fait planter la machine presque syst├®matiquement.
Les trois derniers registres sont beaucoup moins li├®s au fonctionnement interne du processeur. Ils sont mis ├Ā la disposition du programmeur qui peut les modifier ├Ā sa guise et les utiliser comme des registres g├®n├®raux. Comme ces derniers cependant, ils ont une fonction qui leur est propre┬Ā: servir d'index (SI et DI) ou de base (BP). Nous allons expliciter ces deux termes.
Dans la m├®moire, les octets se suivent et forment parfois des cha├«nes de caract├©res. Pour utiliser une cha├«ne, le programmeur doit pouvoir acc├®der facilement ├Ā tous ses octets, l'un apr├©s l'autre. Or pour effectuer une op├®ration quelconque sur un octet, il faut conna├«tre son adresse. Cette adresse doit en g├®n├®ral ├¬tre une constante ├®valuable par le compilateur. Pourquoi une constante ? Parce que l'adresse est un op├®rande comme les autres, elle se trouve imm├®diatement apr├©s l'opcode et doit donc avoir une valeur num├®rique fixe┬Ā!
Prenons un exemple┬Ā:
MOV AH, [MonOctet]
Pas de panique┬Ā! Cette instruction en assembleur signifie ┬½┬ĀMettre dans AH la valeur de l'octet adress├® par le label MonOctet┬Ā!┬Ā┬╗. ├Ć la compilation, ┬½┬ĀMonOctet┬Ā┬╗ sera remplac├® par la valeur num├®rique qu'il repr├®sente et on obtiendra alors une instruction en langage machine telle que┬Ā:
8A260601
8A26 est l'opcode (hexa) de l'instruction ŌĆ£MOV AH, [constante quelconque]ŌĆØ, et 0601 est l'offset de ┬½┬ĀMonOctet┬Ā┬╗.
Il serait pourtant fastidieux, dans le cas d'une cha├«ne de 112 caract├©res, de traiter les octets avec 112 instructions dans lesquelles seule l'adresse changerait. Il faudrait pouvoir faire une boucle sur l'adresse, mais alors celle-ci ne serait plus une constante, d'o├╣ le probl├©me.
Pour les constructeurs du microprocesseur, la seule solution ├®tait de cr├®er de nouveaux opcodes pour chaque op├®ration portant sur un octet en m├®moire. Ces opcodes sp├®ciaux feraient la m├¬me action que ceux dont ils seraient d├®riv├®s, mais l'adresse pass├®e en param├©tre serait alors consid├®r├®e comme un d├®calage par rapport ├Ā un registre sp├®cial. Il suffirait donc de faire varier ce registre, et le processeur y ajouterait automatiquement la valeur de l'op├®rande pour obtenir l'adresse r├®elle┬Ā! C'est ├Ā cela que servent SI, DI et BP.
Par exemple┬Ā:
MOV AH, [MonOctet + DI]
sera cod├®┬Ā:
8AA50601
8AA5 est l'opcode pour l'instruction ŌĆ£MOV AH, [constante quelconque + DI]ŌĆØ.
Remarque┬Ā: les registres SI et BP auraient tout aussi bien pu ├¬tre employ├®s, mais pas les registres g├®n├®raux, SAUF BX. En effet, BX peut jouer exactement le m├¬me r├┤le que BP. N'oubliez pas que BX est appel├® registre de ┬½┬Ābase┬Ā┬╗, et que BP signifie ┬½┬ĀBase Pointer.┬Ā┬╗ Nous verrons la diff├®rence entre une base et un index lorsque nous commencerons l'assembleur.
II-C-5. Le registre des indicateurs▲
Un programme doit pouvoir faire des choix en fonction des donn├®es dont il dispose. Pour cela, il lui faut par exemple comparer des nombres, examiner leur signe, d├®couvrir si une erreur a ├®t├® constat├®e, etc.
Il existe ├Ā cet effet de petits indicateurs, les flags qui sont des bits sp├®ciaux ayant une signification tr├©s pr├®cise. De mani├©re g├®n├®rale, les flags fournissent des informations sur les r├®sultats des op├®rations pr├®c├®dentes.
Ils sont tous regroup├®s dans un registre┬Ā: le registre des indicateurs. Comprenez bien que chaque bit a un r├┤le qui lui est propre et que la valeur globale du registre ne signifie rien. Le programmeur peut lire chacun de ces flags et parfois modifier leur valeur directement.
En mode r├®el, certains flags ne sont pas accessibles. Nous n'en parlerons pas. Nous ne commenterons que les flags couramment utilis├®s.
Nous verrons quelle utilisation on peut faire de ces indicateurs dans la troisi├©me partie de ce tutoriel.
- CF (┬½┬ĀCarry Flag┬Ā┬╗) est l'indicateur de retenue. Il est positionn├® ├Ā 1 si et seulement si l'op├®ration pr├®c├®demment effectu├®e a produit une retenue. De nombreuses fonctions du DOS l'utilisent comme indicateur d'erreur┬Ā: CF passe alors ├Ā 1 en cas de probl├©me.
- PF (┬½┬ĀParity Flag┬Ā┬╗) renseigne sur la parit├® du r├®sultat. Il vaut 1 si ce dernier est pair.
- AF (┬½┬ĀAuxiliary Carry Flag┬Ā┬╗) est peu utilis├®.
- ZF (┬½┬ĀZero Flag┬Ā┬╗) passe ├Ā 1 si le r├®sultat d'une op├®ration est ├®gal ├Ā z├®ro.
- SF (┬½┬ĀSign Flag┬Ā┬╗) passe ├Ā 1 si le r├®sultat d'une op├®ration sur des nombres sign├®s est n├®gatif.
- TF (┬½┬ĀTrap Flag┬Ā┬╗) est utilis├® pour le ┬½┬Ād├®bogage┬Ā┬╗ d'un programme. S'il vaut 1, une routine sp├®ciale du d├®bogueur est appel├®e apr├©s l'ex├®cution de chaque instruction par le processeur.
- IF (┬½┬ĀInterrupt Flag┬Ā┬╗) sert ├Ā emp├¬cher les appels d'interruptions lorsqu'il est positionn├® ├Ā 1. Cependant, toutes les interruptions ne sont pas ┬½┬Āmasquables┬Ā┬╗.
- DF (┬½┬ĀDirection Flag┬Ā┬╗) est utilis├® pour les op├®rations sur les cha├«nes de caract├©res. S'il vaut 1, celles-ci seront parcourues dans le sens des adresses d├®croissantes, sinon les adresses seront croissantes.
- OF (┬½┬ĀOverflow Flag┬Ā┬╗) indique qu'un d├®bordement s'est produit, c'est-├Ā-dire que la capacit├® de stockage a ├®t├® d├®pass├®e. Il est utile en arithm├®tique sign├®e. Avec des nombres non sign├®s, il faut utiliser ZF et SF.
Remarque┬Ā: Les notations CF, PF, AF, etc. ne sont pas reconnues par l'assembleur. Pour utiliser les flags, il existe des instructions sp├®cifiques que nous d├®crirons plus tard.
II-D. LES INTERRUPTIONS▲
II-D-1. Introduction▲
Le microprocesseur ne peut ex├®cuter qu'une seule instruction ├Ā la fois. Pour conna├«tre son adresse, il utilise le couple de registres CS:IP dont la valeur est incr├®ment├®e automatiquement. Par cons├®quent, le code du programme courant est ex├®cut├® de mani├©re lin├®aire.
Imaginons cependant qu'un ├®v├®nement ext├®rieur demande l'attention de l'ordinateur, par exemple la pression d'une touche du clavier. La machine doit pouvoir r├®agir imm├®diatement, sans attendre que le programme en cours d'ex├®cution se termine. Pour cela, elle interrompt ce dernier pendant un bref instant, le temps de traiter l'├®v├®nement survenu puis rend le contr├┤le au programme interrompu.
Une interruption n'est rien d'autre que l'appel d'une routine sp├®ciale pr├®sente en m├®moire appel├®e ISR (┬½┬ĀInterrupt Service Routine┬Ā┬╗).
Les interruptions se divisent en trois cat├®gories┬Ā:
- les interruptions ├®lectroniques, par exemple┬Ā: le clavier┬Ā;
- les interruptions du BIOS, par exemple┬Ā: l'acc├©s aux disques┬Ā;
- les interruptions du DOS, par exemple┬Ā: l'acc├©s aux syst├©mes de fichiers.
Comment sont-elles d├®clench├®es┬Ā?
Une interruption peut ├¬tre d├®clench├®e par votre mat├®riel. C'est ce qui arrive lorsque vous appuyez sur une touche du clavier. Aucun logiciel n'intervient et le contr├┤le est pass├® directement ├Ā la routine qui g├©re le clavier┬Ā: ce sont les interruptions mat├®rielles.
Les interruptions logicielles sont quant ├Ā elles appel├®es par des instructions en langage machine au sein d'un programme. Leur importance est capitale. Rappelez-vous que contrairement au PASCAL ou au C, l'assembleur ne dispose pas de fonction pr├®programm├®e. Chaque instruction doit ├¬tre directement traduisible en langage machine.
Mais alors, comment fait-on pour ├®crire une cha├«ne de caract├©res ├Ā l'├®cran ? Ou bien pour lire un caract├©re entr├® au clavier┬Ā?
Eh bien on le fait de la m├¬me fa├¦on que le DOS lui-m├¬me┬Ā! On d├®clenche les interruptions appropri├®es ├Ā l'aide de l'instruction ┬½┬ĀINT┬Ā┬╗ du langage machine. C'est donc une routine du DOS (ou parfois du BIOS) qui fera tout le travail. Les param├©tres (ou leurs adresses) sont pass├®s dans les registres.
Voici un petit exemple en assembleur qui ├®crit la lettre ŌĆśA' ├Ā l'├®cran┬Ā:

Examinons-le ligne par ligne┬Ā:
- l'instruction ┬½┬ĀMOV DL, ŌĆśA'┬Ā┬╗ demande au processeur de mettre dans le registre DL le code ASCII de la lettre ŌĆśA', c'est-├Ā-dire 65, ou 41h┬Ā;
- ┬½┬ĀMOV AH, 02┬Ā┬╗┬Ā: mettre le nombre 2 dans AH┬Ā;
- enfin, la derni├©re instruction appelle l'interruption num├®ro 21h. Il existe 256 interruptions. Toutes sont not├®es en base hexad├®cimale.
Explications┬Ā:
Comme vous aurez tr├©s vite l'occasion de vous en rendre compte, l'interruption 21h est l'interruption du DOS par excellence. Elle permet d'appeler de nombreuses fonctions tr├©s diverses. Pour cela, il suffit de mentionner leur num├®ro dans le registre AH.
Il est tr├©s difficile de m├®moriser le r├┤le de chaque interruption, et a fortiori de chaque fonction ou sous-fonction, d'autant plus qu'elles sont d├®sign├®es par des num├®ros hexad├®cimaux et qu'elles attendent des param├©tres dans des registres pr├®cis. C'est pourquoi tout programmeur se doit d'avoir ├Ā sa disposition une liste des interruptions pour travailler. Celle de Ralph Brown est tr├©s connue, et vous la trouverez sur l'Internet.
Revenons ├Ā notre exemple. La fonction num├®ro┬Ā2 de l'interruption 21h sert ├Ā ├®crire un caract├©re ├Ā l'├®cran. Il faut pour cela ├®crire le code ASCII du caract├©re dans le registre DL et bien s├╗r placer le nombre 2 dans AH.
Une fois que AH et DL ont ├®t├® ajust├®s, l'interruption 21h peut ├¬tre appel├®e ├Ā l'aide de l'instruction INT.
D'autres interruptions ne remplissent qu'une seule t├óche. Vous n'avez donc pas besoin de mettre un num├®ro de fonction dans AH. L'appel de l'interruption suffit.
II-D-2. La table des vecteurs d'interruptions▲
├Ć chaque appel d'interruption, l'ordinateur doit pouvoir trouver l'adresse de l'ISR correspondante. Pour cela, il dispose de la table des vecteurs d'interruptions (TVI, ou IVT┬Ā: ┬½┬ĀInterrupt Vector Table┬Ā┬╗). Cette table est implant├®e ├Ā l'adresse 0000:0000 c'est-├Ā-dire au d├®but de la RAM.
La table est organis├®e comme suit┬Ā:
| Adresse | Taille (octets) | Valeur |
| 0000:0000 | 2 | Adresse d'offset de l'interruption num├®ro 0 |
| 0000:0002 | 2 | Adresse de segment de l'interruption num├®ro 0 |
| 0000:0004 | 2 | Adresse d'offset de l'interruption num├®ro 1 |
| 0000:0006 | 2 | Adresse de segment de l'interruption num├®ro 1 |
| 0000:0008 | 2 | Adresse d'offset de l'interruption num├®ro 2 |
| 0000:000A | 2 | Adresse de segment de l'interruption num├®ro 2 |
| 0000:000C | 2 | Adresse d'offset de l'interruption num├®ro 3 |
| 0000:000E | 2 | Adresse de segment de l'interruption num├®ro 3 |
| etc. etc. etc. |
||
| 0000:03FC | 2 | Adresse d'offset de l'interruption num├®ro 255 |
| 0000:03FE | 2 | Adresse de segment de l'interruption num├®ro 255 |
La raison pour laquelle les offsets pr├®c├©dent les adresses de segment vient du codage en┬Ā┬½┬Ālittle endian┬Ā┬╗ utilis├® par INTEL. Les processeurs de cette marque (contrairement ├Ā la plupart des autres, qui travaillent en ┬½┬Ābig endian┬Ā┬╗) ont une repr├®sentation des donn├®es en m├®moire aussi curieuse qu'insupportable pour le programmeur┬Ā: ils placent le poids fort apr├©s le poids faible. Ainsi, le mot 4A28h sera cod├® 284Ah. Puisque l'adresse de l'ISR tient sur 32 bits (16 + 16), elle est repr├®sent├®e comme un double-mot (┬½┬Ādword┬Ā┬╗), donc l'adresse d'offset, qui est le mot de poids faible, se trouve au d├®but. Eh oui, c'est p├®nible, mais il faudra s'y faire┬Ā!
Remarque ┬Ā: pour calculer l'adresse de l'entr├®e dans la TVI correspondant ├Ā l'interruption num├®ro X, il suffit de multiplier X par 4.
Exemple┬Ā: l'adresse de l'ISR num├®ro 21h est stock├®e ├Ā 0000:0084.
II-D-3. Sauvegarde de l'├®tat des registres lors de l'appel▲
Un appel d'interruption ob├®it ├Ā certaines r├©gles, car il est indispensable, une fois l'ISR ex├®cut├®e, que le programme interrompu retrouve les registres dans le m├¬me ├®tat qu'ils ├®taient auparavant. Tout doit se passer comme si l'interruption n'avait jamais eu lieu. C'est pourquoi avant de faire un saut ├Ā l'ISR point├®e par l'entr├®e correspondante dans la TVI, l'ordinateur sauvegarde tous les registres sur la pile courante. Il restaurera leur contenu avant de rendre le contr├┤le. Cette proc├®dure est automatique. Il n'incombe pas au programmeur de prendre toutes ces pr├®cautions.
III. DEUXI├łME PARTIE▲
Cette partie a pour but de vous pr├®senter l'architecture du langage assembleur ├Ā travers de courts exemples. Ne vous inqui├®tez pas si vous ne comprenez pas parfaitement certaines instructions┬Ā: toutes seront d├®taill├®es dans la troisi├©me partie. L'essentiel est que vous compreniez grossi├©rement ce qu'on fait et pourquoi on le fait . Les explications qui accompagnent ces exemples devraient y suffire. Vous pourrez ensuite apprendre le langage en lui-m├¬me en consultant la partie suivante.
Remarques pratiques pr├®liminaires┬Ā
- Les mots qui sont imprim├®s en italiques sont ceux qui ne font pas partie du langage en lui-m├¬me. Ils sont choisis par le programmeur.
- Tous les programmes pr├®sent├®s ci-dessous suivent la syntaxe du compilateur TASM. Il existe de tr├©s l├®g├©res diff├®rences d'un compilateur ├Ā l'autre.
- Le code peut ├¬tre ├®crit en majuscules ou en minuscules. Chaque mot est s├®par├® des autres par des espaces ou des tabulations.
- Les commentaires sont pr├®c├®d├®s du signe ŌĆś;'.
- Les nombres doivent toujours commencer par un chiffre (entre 0 et 9), m├¬me les nombres hexad├®cimaux. Il faut donc ├®crire 0F2Ah et non pas F2Ah. Par contre, l'├®criture 5CFh est correcte.
- Les apostrophes et les guillemets sont ├®quivalents. Il est cependant plus commode de r├®server l'usage des guillemets aux cha├«nes de plusieurs caract├©res et celui des apostrophes aux caract├©res isol├®s.
- Vous pouvez taper vos programmes avec l'├®diteur de texte du DOS (EDIT.COM). Donnez-leur l'extension ŌĆś.asm'.
-
La compilation se fait en tapant ŌĆ£TASM /m9 MONPROGŌĆØ si votre source s'appelle ŌĆśMONPROG.ASM'.
Le param├©tre ŌĆś/m9', facultatif, indique au compilateur qu'il devra effectuer 9 passes, c'est-├Ā-dire qu'il examinera 9 fois le code source. Comme chaque examen se fait de mani├©re lin├®aire, le compilateur trouve parfois des instructions qui font r├®f├®rence ├Ā des labels plac├®s plus loin dans le programme. Il manque donc d'informations, mais il continue son examen jusqu'├Ā la fin. Quand il a termin├®, il recommence tout depuis le d├®but pour r├®soudre les probl├©mes qui s'├®taient pos├®s.
La compilation cr├®e un fichier objet (ŌĆś.obj'). Pour obtenir un fichier EXE, tapez ŌĆØTLINK MONPROGŌĆØ. Pour un fichier COM, tapez ŌĆ£TLINK /tdc MONPROGŌĆØ.
Apr├©s l'├®dition des liens (le ┬½┬Ālinkage┬Ā┬╗), vous pouvez supprimer les fichiers MONPROG.obj' et ŌĆśMONPROG.map'.
-
Il est possible de cr├®er un fichier BAT qui s'occupe de toutes ces ├®tapes. Ouvrez l'├®diteur EDIT du DOS et tapez un programme tel que celui-ci┬Ā:
Enregistrez-le et nommez-le MAKE.BAT. Vous pouvez compiler et linker en tapant ŌĆ£MAKE MONPROGŌĆØ. Pour compiler des fichiers COM, ajoutez le param├©tre '/tdc' ├Ā la commande TLINK.
Sélectionnez@ECHO OFF TASM /m9 %1.asm IF NOT EXIST %1.obj GOTO FIN TLINK %1.obj REM┬Ā: ajouter ici /tdc pour obtenir un fichier COM ERASE %1.map ERASE %1.obj :FIN -
Pour pouvoir lancer TASM et TLINK quel que soit le dossier courant, changez la variable PATH ainsi┬Ā:
PATH┬Ā=┬Ā%path%;c:\MonChemin\DossierTASM
Vous pouvez inclure cette ligne ├Ā la fin de votre fichier AUTOEXEC.BAT afin qu'elle soit ex├®cut├®e ├Ā chaque d├®marrage.
- Vous pouvez d├®boguer vos programmes (par exemple les ex├®cuter instruction par instruction en observant les changements induits dans la RAM et dans les registresŌĆ”) avec le logiciel Turbo Debugger 16/32 bits qui est tr├©s pratique et tr├©s performant. ├Ć d├®faut, vous pouvez vous rabattre sur l'archa├»que DEBUG.COM (il se trouve dans votre dossier de commandes DOS). Mais alors bon courage┬Ā!
Le seul travail du compilateur (et du linkeur) est de convertir chacune de vos instructions en son ├®quivalent en langage machine. Le programme compil├® pr├®sentera donc exactement la m├¬me structure et la m├¬me lin├®arit├® que votre code source .
III-A. PREMIER EXEMPLE : LES FICHIERS COM▲
Voici un petit programme COM qui ├®crit le message ┬½┬ĀBonjour, monde┬Ā!┬Ā┬╗ ├Ā l'├®cran.

Ce code source commence par des┬Ādirectives. Une directive est une information que le programmeur fournit au compilateur.┬ĀElle n'est pas transform├®e en une instruction en langage machine.┬ĀElle n'ajoute donc aucun octet au programme compil├®.
La directive ŌĆ£.386ŌĆ£ indique au compilateur que le programme est destin├® ├Ā tourner sur des processeurs INTEL de mod├©le 386 (ou sup├®rieur). Cela nous autorise ├Ā utiliser certaines instructions qui ne sont pas disponibles sur les mod├©les ant├®rieurs, comme PUSHA ou POPA. Dans cet exemple, cette directive aurait tr├©s bien pu ├¬tre omise.
La ligne
code┬Āsegment use16
sert ├Ā d├®clarer un segment que l'on appelle ŌĆ£codeŌĆØ. On aurait tout aussi bien pu le nommer ŌĆ£marteauŌĆØ ou ŌĆ£voitureŌĆØ. Ce sera le segment de notre programme. N'oubliez pas qu'un fichier COM ne peut comporter qu'un seul segment. Cette ligne ne sera pas compil├®e┬Ā: elle ne sert qu'├Ā indiquer au compilateur le d├®but d'un segment.
Le mot ŌĆ£use16ŌĆØ indique que les adresses de segment et d'offset sont cod├®es sur 16 bits et non sur 8 bits. Vous devez syst├®matiquement l'├®crire.
La directive
assume cs:code, ds:code, ss:code
informe le compilateur que tout au long du programme, CS, DS et SS pointeront de fa├¦on privil├®gi├®e vers le segment ŌĆ£codeŌĆØ, ce qui est ├®vident d'ailleurs puisque c'est le seul segmentŌĆ” Vous comprendrez le sens exact de ŌĆ£assumeŌĆØ dans la troisi├©me partie du cours.
Enfin, les mots
org┬Ā100h
signifient qu'il faudra ajouter 100h (soit 256) ├Ā tous les offsets. Pourquoi┬Ā? Souvenez-vous de la structure d'un programme COM en m├®moire. Si vous n'├®crivez pas cette ligne, TASM consid├®rera que le programme d├®bute ├Ā l'offset 0000. Or, lors de l'ex├®cution, le DOS le chargera apr├©s le PSP, c'est-├Ā-dire ├Ā l'adresse 100h. C'est pourquoi il est n├®cessaire de recalculer les offsets┬Ā: l'offset 0000 deviendra 0100.┬ĀCette directive est en quelque sorte le trait caract├®ristique des fichiers COM.
Nous en arrivons au programme proprement dit. Il commence par un label┬Ā:
debut┬Ā:
Lui non plus n'est pas compil├®. Il ne sert qu'├Ā repr├®senter l'adresse de l'instruction qui le suit, c'est-├Ā-dire┬Ā:
mov ah,┬Ā09h
Cette ligne demande au processeur de charger la valeur 9 dans le registre AH. C'est le num├®ro de la fonction de l'interruption 21h qui ├®crit une cha├«ne de caract├©res ├Ā l'├®cran. L'offset de cette cha├«ne est attendu dans DX. D'o├╣ la ligne suivante┬Ā:
mov dx, offset┬Āmessage
Le mot-cl├® ŌĆ£offsetŌĆØ sert ├Ā extraire l'offset du label ŌĆ£messageŌĆØ qui repr├®sente quant ├Ā lui l'adresse du message ├Ā ├®crire (il contient donc une adresse de segment ET un offset). L'adresse de segment de la cha├«ne doit ├¬tre transmise dans DS. Mais il est inutile de changer ce registre, car il pointe d├®j├Ā vers notre segment.
Il nous reste ├Ā appeler l'interruption 21h┬Ā:
int┬Ā21h
et ├Ā rendre la main au DOS┬Ā:
ret
Lorsque nous aborderons les proc├®dures, vous comprendrez mieux le sens de ce mot et ce qu'il fait exactement. Pour l'instant, sachez simplement que seul un fichier COM peut se terminer avec cette instruction.
Nous arrivons ├Ā la ligne┬Ā:
message┬Ādb ŌĆ£Bonjour, monde┬Ā!ŌĆØ, ŌĆś$'
Il s'agit d'une d├®finition de donn├®es. Le mot ŌĆ£dbŌĆØ (┬½┬Ādefine byte┬Ā┬╗) signifie que le compilateur devra ├®crire les octets qui suivent tels qu'ils sont dans notre code source. Il va donc ├®crire le code ASCII du ŌĆśB', puis celui du ŌĆśo', etc. Il terminera en ├®crivant le code ASCII du signe ŌĆś$'. C'est ainsi que la fonction 9 de l'interruption 21h reconna├«t la fin de la cha├«ne ├Ā ├®crire. Si vous oubliez ce signe, elle ├®crira tous les octets de la RAM jusqu'├Ā ce qu'elle tombe par hasard sur lui.
Le mot ŌĆ£messageŌĆØ plac├® en d├®but de ligne est un label de donn├®es. Il repr├®sente┬Āl'adresse┬Ādu code ASCII du ŌĆśB'.┬ĀRemarquez qu'il n'y a pas de caract├©re ŌĆś:' apr├©s un label de donn├®es.
La ligne
code┬Āends
indique la fin du segment ┬½┬Ācode┬Ā┬╗, et enfin
end┬Ādebut
informe le compilateur que le fichier est fini, tout comme le ŌĆ£END.ŌĆØ du PASCAL. Le nom du label ┬½┬Ādebut┬Ā┬╗ est mentionn├®┬Ā: ce sera le point d'entr├®e de notre programme. C'est vers lui que pointera CS:IP avant l'ex├®cution.
Remarque┬Ā: vous n'├¬tes pas tenu de rendre aux registres la valeur qu'ils avaient au d├®but de votre programme. De toute fa├¦on, avant de charger un programme, le DOS sauvegarde le contenu de tous les registres puis met le contenu des registres g├®n├®raux (ainsi que SI, DI et BP) ├Ā z├®ro. Il les restaurera quand vous lui rendrez la main.
III-B. DEUXI├łME EXEMPLE : LES FICHIERS EXE▲
Le programme suivant est un programme EXE qui fait exactement la m├¬me chose que l'exemple pr├®c├®dent.

Examinons-le┬Ā!
Tout d'abord, la directive
org┬Ā100h
a disparu.
En effet, lors de l'ex├®cution, CS pointera vers notre segment de code et non pas vers le PSP. Il est donc inutile de d├®caler les offsets de 256.
Remarquons que notre programme dispose de deux segments suppl├®mentaires┬Ā:
- le segment ┬½┬Ādata┬Ā┬╗ est destin├® ├Ā contenir les donn├®es, c'est-├Ā-dire les variables┬Ā;
- le segment ┬½┬Āpile┬Ā┬╗ sera notre segment de pile.
Notre directive ┬½┬Āassume┬Ā┬╗ devient donc┬Ā:
assume cs:code, ds:data, ss:pile
Ainsi, le compilateur est inform├® que DS pointera vers le segment ┬½┬Ādata┬Ā┬╗ et SS vers ┬½┬Āpile┬Ā┬╗.
Les deux lignes suivantes,
mov ax,┬Ādata
mov ds, ax
servent ├Ā initialiser le registre DS. Celui-ci pointe vers le PSP au d├®but du programme, mais nous voulons le faire pointer vers notre segment de donn├®es appel├® ┬½┬Ādata┬Ā┬╗. Cela est n├®cessaire puisque la fonction 9 de l'interruption 21h attend l'adresse de la cha├«ne dans le couple DS:DX et que notre message se trouve dans le segment de donn├®es.
La premi├©re instruction charge l'adresse du segment ┬½┬Ādata┬Ā┬╗ dans AX. La seconde transf├©re cette valeur de AX dans DS.
Mais pourquoi diable utiliser AX comme interm├®diaire┬Ā? Apr├©s tout, on pourrait ├®crire┬Ā:
mov ds,┬Ādata
Eh bien non┬Ā!┬ĀPour la simple raison que DS est un registre de segment et qu'en tant que tel on ne peut pas lui charger de valeur imm├®diate.
On appelle ┬½┬Āvaleur imm├®diate┬Ā┬╗ toute constante tap├®e directement dans l'instruction elle-m├¬me.
Exemples de chargement de valeurs┬Āimm├®diates┬Ā:
mov ax,┬Ā135┬Ā;charge 135 dans AX
mov bx, offset┬Āmessage┬Ā;charge l'offset de message dans BX
mov bx, offset┬Āfin┬Ā- offset┬Ādebut┬Ā;charge le nombre d'octets entre fin et debut dans BX
mov es,┬Ā10┬Ā;instruction illicite, car ES est un registre de segment┬Ā!
Remarque┬Ā: une autre possibilit├® aurait ├®t├® d'├®crire┬Ā: ŌĆ£PUSH AXŌĆØ (empiler AX) puis ŌĆ£POP DSŌĆØ (d├®piler le dernier nombre empil├® et le placer dans DS).
Les trois lignes suivantes┬Ā:
mov ah,┬Ā09h
mov dx, offset┬Āmessage
int┬Ā21h
n'ont pas chang├®.
Il nous faut ├®galement terminer le programme par un appel de la fonction 4ch de l'interruption 21h. C'est ainsi que se terminent les programmes EXE.
mov ah,┬Ā4ch
int┬Ā21h
Remarque┬Ā: on aurait ├®galement pu ├®crire┬Ā:
mov ax,┬Ā4c00h
int┬Ā21h
La seule diff├®rence est que AL est mis ├Ā z├®ro, ce qui indique au programme ├Ā qui on rend le contr├┤le (ici le DOS) que notre programme s'est termin├® normalement. Les fichiers COM peuvent ├®galement utiliser la fonction 4ch.
Le segment de code se termine┬Ā:
code┬Āends
et le segment de donn├®es commence ├Ā sa suite┬Ā:
data┬Āsegment use16
message┬Ādb ŌĆ£Bonjour, monde┬Ā!ŌĆØ, ŌĆś$'
data┬Āends
Il nous reste ├Ā ├®crire le segment de pile. Dans ce programme, il n'├®tait pas absolument indispensable de le s├®parer du segment de code. Mais c'est une bonne habitude de le faire.
pile┬Āsegment stack
remplissage┬Ādb┬Ā256┬ĀDUP (?)
pile┬Āends
Le mot-cl├® ┬½┬Āstack┬Ā┬╗ indique que ce segment est le segment de pile.
Les mots ┬½┬Ādb┬Ā256┬ĀDUP (?)┬Ā┬╗ d├®clarent 256 octets non initialis├®s. C'est la ┬½┬Āmati├©re┬Ā┬╗ de notre pile.
Sachez que tout appel d'interruption se traduit par l'empilage des flags et de CS:IP. Il est donc indispensable d'avoir une pile, m├¬me si celle-ci peut ├®ventuellement partager le m├¬me segment que le code, comme dans un fichier COM. Mais dans un programme EXE, il vaut mieux r├®server un segment ├Ā la pile. Les 256 octets que nous d├®clarons ici indiquent seulement que la pile contient 256 octets. Ainsi, au d├®but de l'ex├®cution, SS:SP pointera vers la fin de ces octets. Nous verrons ce que signifie le point d'interrogation dans la troisi├©me partie.
La fin du fichier et le point d'entr├®e sont signal├®s par┬Ā:
end┬Ādebut
Et voil├Ā┬Ā! Vous avez d├®couvert l'allure d'un programme en assembleur. Nous pouvons donc ├Ā pr├®sent nous pencher sur l'├®tude du langage.
IV. TROISI├łME PARTIE▲
IV-A. D├ēFINITION DE DONN├ēES ET ADRESSAGE▲
IV-A-1. Les d├®finitions de donn├®es▲
Les mots ŌĆ£dbŌĆØ (┬½┬Ādefine byte┬Ā┬╗), ŌĆ£dwŌĆØ (┬½┬Ādefine word┬Ā┬╗), ŌĆØddŌĆØ (┬½┬Ādefine double word┬Ā┬╗) permettent de d├®clarer et d'initialiser une variable. Il faut bien comprendre que leur seule action est d'├®crire les donn├®es dans l'ex├®cutable ├Ā l'endroit m├¬me o├╣ elles se trouvent dans le code source.
Pour acc├®der ├Ā ces donn├®es (appel├®es ┬½┬Āvariables┬Ā┬╗), il suffit de conna├«tre leur adresse. Pour cela, on peut les faire pr├®c├®der d'un label de donn├®es.
Exemple┬Ā:
TOTO dw 1982
Dans la ligne pr├®c├®dente, TOTO repr├®sente l'adresse du nombre 1982 qui est d├®fini juste apr├©s. Comme ce nombre est cod├® sur deux octets (word =┬Ā16 bits), c'est le premier octet qui est adress├® par TOTO.
Le compilateur se contentera d'├®crire le nombre 1982 ├Ā l'endroit o├╣ se trouve la d├®claration.
Remarque┬Ā: en C, on ├®crirait ceci┬Ā:
int TOTO┬Ā=┬Ā1982;
En BASIC ou en PASCAL, cette d├®finition n'a pas d'├®quivalent, puisque les variables ne peuvent ├¬tre initialis├®es lors de leur d├®claration. Il est donc obligatoire d'ajouter une ligne de code pour le faire.
Dans la partie pr├®c├®dente, nous avons eu ├Ā d├®finir le message qui serait affich├® ├Ā l'├®cran. Voici la ligne que nous avons ├®crite┬Ā:
message┬Ādb ŌĆ£Bonjour, monde┬Ā!ŌĆØ, ŌĆś$'
Lorsqu'il rencontre une cha├«ne de caract├©res, le compilateur ├®crit┬Āles codes ASCII┬Āde tous les caract├©res, les uns ├Ā la suite des autres.
Voici une autre mani├©re d'├®crire cette d├®finition de donn├®es. Le r├®sultat (i.e. le programme compil├®) est EXACTEMENT LE M├ŖME┬Ā:
message┬Ādb┬Ā42h,┬Ā111, ŌĆśnj'
db ŌĆśour, mo'
db ŌĆśnde┬Ā!$'
Pour d├®finir plusieurs fois ├Ā la suite les m├¬mes donn├®es, on utilise ŌĆ£DUPŌĆØ (┬½┬Āduplicate┬Ā┬╗) de la mani├©re suivante┬Ā:
TOTO┬Ādb┬Ā100┬Ādup(ŌĆ£TOTO EST BEAUŌĆØ)
Cela revient ├Ā ├®crire┬Ā:
TOTO┬Ādb ŌĆ£TOTO EST BEAUŌĆØ
TOTO┬Ādb ŌĆ£TOTO EST BEAUŌĆØ
TOTO┬Ādb ŌĆ£TOTO EST BEAUŌĆØ
;ŌĆ” etc. (100 fois) ŌĆ”
Il est fr├®quent que de nombreuses donn├®es n'aient pas besoin d'├¬tre initialis├®es ├Ā une valeur pr├®cise. Dans ce cas, on les regroupe ├Ā la fin du programme et on les remplace par le caract├©re ŌĆś?'. Les adresses des labels seront calcul├®es de la m├¬me fa├¦on, mais aucune donn├®e ne sera ├®crite dans le fichier (et a fortiori dans la RAM). On dit que l'on met ses variables sur le ┬½┬Ātas┬Ā┬╗ (┬½┬Āheap┬Ā┬╗ en anglais). La seule diff├®rence avec une d├®finition classique est qu'au d├®but de l'ex├®cution, nos variables n'auront pas de valeur d├®finie. Leurs valeurs seront ┬½┬Āal├®atoires┬Ā┬╗ en ce sens qu'on ne peut les conna├«tre au moment de la compilation.
Exemple ┬Ā:

Remarque┬Ā: Si elles ne sont pas regroup├®es en fin de programme, le compilateur sera oblig├® d'├®crire les donn├®es dans le fichier afin de ne pas fausser les adresses des variables (ou du code) qui suivent. Il remplira alors les points d'interrogation avec des z├®ros.
Pour indiquer qu'un nombre est not├® en base hexad├®cimale, on lui ajoute la lettre ŌĆśh'. La lettre ŌĆśb' signifie que le nombre est cod├® en binaire, la lettre 'o' en octal et la lettre ŌĆśd' en base d├®cimale (base par d├®faut).
IV-A-2. L'adressage▲
IV-A-2-a. L'adressage imm├®diat▲
On appelle ┬½┬Āadressage imm├®diat┬Ā┬╗ l'adressage qui ne fait intervenir que des constantes.
Consid├®rons cette partie de programme qui stocke le nombre 125h dans une variable appel├®e TOTO, lui ajoute 15 puis charge le r├®sultat dans AX.

La ligne
mov word ptr ds:[TOTO],┬Ā125h
charge le nombre 125h dans le mot de la RAM adress├® par DS et l'offset de ŌĆ£TOTOŌĆØ. La ligne suivante ajoute 15 au contenu de ce mot.
L'expression ŌĆ£word ptrŌĆØ devant l'adresse, obligatoire ici, indique la taille de la variable dans laquelle doit ├¬tre stock├® le nombre 125h.
Si on avait mis ŌĆ£dword ptrŌĆØ, ce nombre aurait ├®t├® cod├® sur 32 bits (00000125h) au lieu de 16 bits (0125h)┬Ā: on aurait donc ├®cras├® les deux octets qui suivent la variable. Si on avait mis ŌĆ£byte ptrŌĆØ, la compilation aurait ├®t├® impossible, car un octet ne peut contenir un nombre sup├®rieur ├Ā FFh.
Le compilateur n'a en effet aucun moyen de conna├«tre cette taille.┬ĀLa variable ŌĆ£TOTOŌĆØ n'a pas de taille (malgr├® le mot ŌĆ£dwŌĆØ)┬Ā: ce n'est en fait qu'un pointeur vers le premier octet du┬Āword┬Āqu'elle repr├®sente.
En revanche, la troisi├©me instruction ne fait pas appara├«tre l'expression ŌĆ£word ptrŌĆØ. Cette fois-ci elle est facultative du fait que la destination (AX =┬Ā16 bits) impose la taille.
On peut ├®videmment remplacer ŌĆ£TOTOŌĆØ par une constante num├®rique┬Ā:
mov word ptr ds:[004Ch],┬Ā125h
Le mot 125h sera alors ├®crit ├Ā l'adresse DS:4C.
Une question se pose ├Ā pr├®sent┬Ā:┬Āque se passe-t-il si le programmeur n'├®crit pas le registre de segment dans l'adresse┬Ā?
C'est l├Ā qu'intervient la directive ŌĆ£assumeŌĆØ. Le compilateur va devoir trouver lui-m├¬me quel registre l'utilisateur a voulu sous-entendre.
Si on a utilis├® un label, alors le segment sera celui dans lequel est d├®clar├® le label. Mais le compilateur veut un REGISTRE de segment. Il va donc prendre celui qui est cens├® pointer vers le bon segment et pour le savoir, il examine la directive assume.
Voil├Ā pourquoi cette derni├©re peut nous ├®pargner d'├®crire pour chaque variable l'expression ŌĆ£ds:ŌĆØ.
Comprenez bien que cette directive ne sert ├Ā rien d'autre qu'├Ā cela et qu'en aucune fa├¦on elle ne force les registres de segment ├Ā prendre quelque valeur que ce soit.
IV-A-2-b. L'adressage index├® et/ou bas├®▲
Comme nous l'avons d├®j├Ā expliqu├®, il est possible d'utiliser des registres de┬Ābase┬Āou d'index┬Āpour adresser un octet.
On appelle ┬½┬Ābase┬Ā┬╗ les registres BX et BP et ┬½┬Āindex┬Ā┬╗ les registres SI et DI. La diff├®rence est que la base est cens├®e ├¬tre fixe tandis que l'index varie automatiquement lorsqu'on utilise certaines op├®rations, telles que MOVSB.
Remarque┬Ā: BX, BP, DI et SI peuvent tous ├¬tre utilis├®s comme des registres g├®n├®raux.
Voici les adressages possibles :
- Constante seule (=┬Āadressage imm├®diat)┬Ā:
Exemples┬Ā:
MOV AH, byte ptr [TOTO]
MOV BX, word ptr ds:[1045h]
MOV ES:[10┬Ā+┬ĀTOTO┬Āx┬Ā2], BL
- Base seule┬Ā:
Exemple┬Ā:
MOV dword ptr ds:[BP],┬Ā15
- Index seul┬Ā:
Exemple┬Ā:
MOV dword ptr es:[DI],┬Ā142
- Base + Constante┬Ā:
Exemples┬Ā:
MOV byte ptr ds:[BP +┬Ā1],┬Ā12
MOV ds:[BX + (TOTO┬Ā-┬ĀBOBO)/10], AX
- Index + Constante┬Ā:
Exemples┬Ā:
MOV CX, [TOTO┬Ā+ DI]
MOV AL, ds:[1┬Ā+ SI]
- Base + Index┬Ā:
Exemple┬Ā:
MOV ds:[BP + SI], AH
- Base + Index + Constante┬Ā:
Exemple┬Ā:
MOV AX, word ptr [TOTO┬Ā+ BX + DI +┬Ā1]
Remarque┬Ā: si la constante n'est pas un label, il est parfois imp├®ratif de sp├®cifier le registre de segment┬Ā! Tout d├®pend du contexteŌĆ”
IV-B. SAUTS INCONDITIONNELS, PROC├ēDURES ET MACROS▲
IV-B-1. Les sauts inconditionnels▲
Ce paragraphe r├®pond ├Ā la question┬Ā: ┬½┬ĀMais comment fait-on un GOTO en assembleur┬Ā?┬Ā┬╗.
L'instruction ├®quivalente est JMP qui signifie ┬½┬Ājump┬Ā┬╗.
La syntaxe est
JMP MonLabel
La r├®f├®rence ├Ā l'├®tiquette MonLabel sera remplac├®e lors de la compilation par la distance (sign├®e) en octets qui s├®pare l'instruction qui suit imm├®diatement le JMP de l'instruction adress├®e par MonLabel. En pratique, le JMP s'utilise exactement comme un GOTO en BASIC.
Cette instruction permet de faire un saut inconditionnel┬Ā: le programme fera ce saut quoi qu'il arrive.
Exemple┬Ā:

Le mot ŌĆ£shortŌĆØ ajout├® apr├©s ŌĆ£jmpŌĆØ indique au compilateur que le label ŌĆ£COUCOUŌĆØ se trouve ├Ā une distance (sign├®e) qui peut ├¬tre stock├®e sur un seul octet. Le compilateur ne le sait pas encore lorsqu'il essaie de compiler l'instruction de saut, car le label se trouve en de├¦├Ā de cette instruction. C'est pourquoi il pr├®voit deux octets pour ├®crire le saut, au cas o├╣ l'adresse d'arriv├®e est ├®loign├®e de plus de 128 octets. Lorsqu'il effectue une deuxi├©me ┬½┬Āpasse┬Ā┬╗, s'il s'aper├¦oit qu'un seul octet aurait suffi il remplit alors l'octet inutile avec l'instruction NOP (┬½┬ĀNo Operation┬Ā┬╗) qui ne fait rien du tout. Le programme marchera parfaitement (encore heureux┬Ā!), mais cela gaspille un octet. Le programmeur a la possibilit├® d'aider le compilateur en ajoutant le mot ŌĆ£shortŌĆØ, ainsi un seul octet est pr├®vu pour la distance de saut. Si le label est plac├® plus haut que l'instruction de saut, il est inutile de l'├®crire.
Remarque┬Ā: Ce mot peut ├®galement ├¬tre utilis├® avec les instructions de saut conditionnel que nous ├®tudierons plus loin.
IV-B-1-a. Les proc├®dures▲
IV-B-1-a-i. appels de proc├®dures▲
Ceux qui ont d├®j├Ā programm├® en BASIC connaissent les instructions GOSUB et RETURN. Leurs ├®quivalents en assembleur sont CALL et RET.
- L'instruction CALL sert ├Ā appeler une proc├®dure┬Ā:
Syntaxe┬Ā:
CALL MonLabel
Action┬Ā: empile l'offset de l'instruction suivante puis fait un simple saut ├Ā l'adresse repr├®sent├®e par MonLabel.
- RET (ou RETN) permet de retourner ├Ā l'instruction qui suit imm├®diatement le CALL┬Ā:
Syntaxe┬Ā:
RET
Action┬Ā: d├®pile l'adresse de retour et la met dans IP. Le programme continue donc ├Ā l'adresse qui suit le CALL.
Remarque┬Ā: Rappelez-vous qu'il est possible de terminer un programme COM avec l'instruction RET. Puisque le DOS empile un z├®ro de deux octets au chargement du programme, IP prendra la valeur 0000 lorsque le processeur ex├®cutera cette instruction┬Ā: il pointera donc vers le d├®but du PSP. Or le PSP commence toujours par les deux octets suivants┬Ā: CDh 20h (ce qui s'├®crit INT 20h en assembleur). L'interruption 20h, qui permet de terminer un programme COM, sera donc appel├®e et le contr├┤le sera rendu au DOS.
Voici un exemple d'utilisation des proc├®dures aussi simple que possible┬Ā: ce programme COM appelle 12 fois une proc├®dure qui ├®crit un message ├Ā l'├®cran et rend la main au DOS. Il n'est d'aucune utilit├® et n'est pas optimis├® du tout.

Remarque┬Ā: Les codes ASCII 10 et 13 repr├®sentent respectivement la fin de ligne et le retour chariot. Gr├óce ├Ā eux, on revient ├Ā la ligne chaque fois qu'on a ├®crit le message.
Ce programme fonctionne parfaitement. Toutefois, les conventions d'├®criture veulent que les proc├®dures soient ├®crites comme suit┬Ā:

Le programme compil├® est toujours le m├¬me, mais le code est plus lisible puisqu'on distingue les proc├®dures des simples labels. Le mot ŌĆ£nearŌĆØ signifie que l'adresse de cette proc├®dure est r├®duite ├Ā un offset. Il n'y a pas d'adresse de segment. La proc├®dure ne pourra donc ├¬tre appel├®e que de l'int├®rieur m├¬me du segment.
Le mot qui a le sens contraire de ŌĆ£nearŌĆØ est ŌĆ£farŌĆØ. Les ┬½┬Ācall far┬Ā┬╗ sont assez peu utilis├®s.
IV-B-1-a-ii. le passage des param├©tres▲
Il existe deux moyens de passer des param├©tres ├Ā une proc├®dure┬Ā: les registres et la pile.
- Le passage par registres┬Ā:
Il consiste ├Ā transmettre les param├©tres dans des registres convenus ├Ā l'avance, par exemple AX et BX. Les deux gros avantages de cette m├®thode sont sa simplicit├® et la vitesse d'ex├®cution. L'inconv├®nient majeur est le nombre limit├® de registres, d'autant plus qu'au moment de l'appel, certains d'entre eux ne seront peut-├¬tre pas disponibles.
- Le passage par la pile┬Ā:
C'est la m├®thode qu'utilisent les langages de haut niveau tels que le C ou le PASCAL. Avant l'appel, on empile les param├©tres un ├Ā un. La proc├®dure appel├®e se chargera de les lire.
Pour cela on utilise le registre BP de la mani├©re suivante┬Ā: on transf├©re la valeur de SP dans BP ├Ā l'aide de l'instruction ŌĆ£MOV BP, SPŌĆØ. L'adresse de retour (qui sera d├®pil├®e quand le processeur rencontrera l'instruction ŌĆ£RETŌĆØ) se trouve ├Ā l'adresse SS:[BP], le dernier param├©tre est adress├® par SS:[BP + 2], l'avant-dernier par SS:[BP + 4], etc. On peut ainsi lire n'importe quel param├©tre sans le d├®piler.
Attention cependant┬Ā! ├Ć la fin de la proc├®dure, il faudra tout de m├¬me rendre ├Ā SP la valeur qu'il avait avant l'empilage des param├©tres. Pour cela, on fait suivre l'instruction RET du nombre de param├©tres, multipli├® par 2 (car chaque param├©tre comporte deux octets).
Exemple┬Ā:

Soyez toujours tr├©s vigilant avec les appels de proc├®dures┬Ā: pensez que l'adresse de retour sera d├®pil├®e lorsque le programme rencontrera l'instruction RET. Il serait donc suicidaire de laisser une donn├®e empil├®e avant d'appeler cette instruction.
IV-B-1-b. Les macros▲
├ētant donn├® que certaines instructions se r├®p├©tent constamment dans un programme, l'├®criture de macrofonctions (ou macros) est un moyen pratique de rendre votre code source plus lisible.
Il est possible de choisir pour certaines suites d'instructions un nom qui les repr├®sente. Lorsque le compilateur (en fait, le pr├®processeur) rencontrera ce nom dans votre code source, il le remplacera par les lignes de code qu'il d├®signe. Ces lignes forment une ┬½┬Āmacro┬Ā┬╗.
Les macros, ├Ā la diff├®rence des proc├®dures, n'ont aucune signification pour la machine. Seul le compilateur comprend leur signification. Elles ne sont qu'un artifice mis ├Ā la disposition du programmeur pour clarifier son programme. Lorsque le compilateur rencontre le nom d'une macro dans votre code, il le remplace par le code de la macro. Tout se passe exactement comme si vous aviez tap├® vous-m├¬me ce code ├Ā la place du nom de la macro.
Ainsi, si vous appelez quinze fois une macro dans votre programme, le compilateur ├®crira quinze fois le code de cette macro. C'est toute la diff├®rence avec les proc├®dures qui ne sont ├®crites qu'une seule fois, mais peuvent ├¬tre appel├®es aussi souvent qu'on veut ├Ā l'aide d'un CALL.
Voici comment ├®crire une macro┬Ā: l'exemple suivant sert ├Ā ├®crire un message ├Ā l'├®cran.

Le code pr├®c├®dent peut ├¬tre ├®crit n'importe o├╣ dans votre programme, ├Ā condition qu'il se trouve avant tout appel de cette macro. Afin d'├®viter les ennuis, il est fortement conseill├® de r├®unir vos macros au d├®but du code, avant toute autre ligne. De toute fa├¦on, il ne sera pas compil├® ├Ā l'endroit o├╣ vous l'avez ├®crit, mais aux endroits o├╣ se trouvent les appels de macros.
Le mot ŌĆ£text?ŌĆØ est un ┬½┬Āparam├©tre┬Ā┬╗. Le point d'interrogation n'est pas requis ; nous l'avons mis pour indiquer qu'il s'agit d'un param├©tre et non d'une variable. Une macro peut utiliser plusieurs param├©tres s├®par├®s par des virgules.
Pour appeler cette macro, il vous suffit d'├®crire la ligne
ecrit_texte ŌĆ£Coucou┬Ā! Ceci est un essai┬Ā!ŌĆØ
Le compilateur se chargera alors de la remplacer par les instructions comprises entre la premi├©re et la derni├©re ligne de cet exemple, en prenant le soin de remplacer le mot ŌĆ£text?ŌĆØ par le message fourni en param├©tre.
En assembleur, chaque label doit avoir un nom unique. Or, si une macro est appel├®e plusieurs fois, les m├¬mes noms seront utilis├®s. Il faut donc la plupart du temps inclure la directive LOCAL qui forcera le compilateur ├Ā changer le nom des labels ├Ā chaque appel de la macro. Attention┬Ā: cette directive doit suivre imm├®diatement la d├®claration de la macro.
Supposons ├Ā pr├®sent que l'on veuille ├®crire ├Ā l'├®cran le message ┬½┬ĀJe suis bien content┬Ā┬╗ et revenir ├Ā la ligne ├Ā l'aide de notre macro ecrit_texte.
La syntaxe suivante┬Ā:
ecrit_texte ŌĆ£Coucou┬Ā! Ceci est un essai┬Ā!ŌĆØ, 10, 13
est incorrecte, car le compilateur croirait que l'on a ├®crit trois param├©tres┬Ā! Il faut alors entourer notre unique param├©tre par les signes ŌĆś<' et ŌĆś>'┬Ā:
ecrit_texte <ŌĆØCoucou┬Ā! Ceci est un essai┬Ā!ŌĆØ, 10, 13>
IV-B-1-c. La directive EQU▲
La directive EQU a un r├┤le voisin de celui des macros. Elle permet de remplacer un simple mot par d'autres plus complexes. Son int├®r├¬t est qu'elle peut ├¬tre invoqu├®e en plein milieu d'une ligne.
Quelques exemples┬Ā:
Longueur EQU (fin - debut)
Message EQU ŌĆ£Bonjour messieurs┬Ā! Comment allez-vous ?ŌĆØ, ŌĆś$'
Version EQU 2
Quitter EQU ret
Quitter2 EQU int 20h
Mettre_dans_AH EQU mov ah,
Interruption_21h EQU int 21h
Un programme qui contient de telles directives peut se terminer ainsi┬Ā:
Mettre_dans_AH 4Ch
Interruption_21h
Ou ainsi (si c'est un COM)┬Ā:
Quitter2
IV-B-1-d. L'inclusion de fichiers▲
Il est possible d'acc├®der ├Ā des proc├®dures, des macros ou des d├®finitions EQU qui se trouvent dans d'autres fichiers. Cela permet de se constituer des biblioth├©ques de macros ou de proc├®dures que l'on peut r├®utiliser d'un programme ├Ā l'autre.
Pour inclure le fichier TOTO.LIB, ├®crivez au d├®but de votre code source┬Ā:

La condition ŌĆ£if1ŌĆØ indique au compilateur que l'inclusion ne doit s'effectuer que lors de la premi├©re passe.
Le fichier TOTO.LIB est un fichier texte tout ├Ā fait banal qui contient des lignes de code en assembleur.
IV-C. LES PRINCIPALES INSTRUCTIONS DU LANGAGE MACHINE▲
Remarques pr├®liminaires┬Ā:
- Le principe du langage assembleur est de remplacer chaque opcode hexad├®cimal par un mot facile ├Ā retenir. Ce mot est appel├® mn├®monique. Par exemple, ŌĆ£INTŌĆØ est le mn├®monique associ├® ├Ā l'opcode CDh. Chaque fois que le compilateur rencontrera ce mot, il le remplacera par l'octet CDh et ├®crira ensuite l'op├®rande (ici┬Ā: le num├®ro de l'interruption) en hexad├®cimal.
- Cette liste r├®capitule les instructions que nous connaissons d├®j├Ā et en pr├®sente de nouvelles. Elle n'est pas exhaustive, mais vous sera amplement suffisante pour la plupart de vos programmes.
- Certaines instructions, comme PUSHA, ne sont disponibles que pour des mod├©les de processeurs plus ├®volu├®s que le 8086, par exemple le 286. N'oubliez pas la directive .386 si vous les utilisez.
IV-C-1. L'instruction NOP (┬½ No Operation ┬╗)▲
Syntaxe┬Ā: NOP
Description┬Ā: Ne fait rien┬Ā! Mais alors RIEN┬Ā! Que dalle┬Ā! Niet┬Ā!
IV-C-2. L'instruction MOV (┬½ Move ┬╗)▲
Syntaxe┬Ā: MOV Destination, Source
Description┬Ā: Copie le contenu de Source dans Destination.
Mouvements autoris├®s┬Ā:
MOV Registre g├®n├®ral, Registre quelconque
MOV M├®moire, Registre quelconque
MOV Registre g├®n├®ral, M├®moire
MOV Registre g├®n├®ral, Constante
MOV M├®moire, Constante
MOV Registre de segment, Registre g├®n├®ral
Remarques┬Ā: Source et Destination doivent avoir la m├¬me taille. On ne peut charger dans un registre de segment que le contenu d'un registre g├®n├®ral (SI, DI et BP sont consid├®r├®s ici comme des registres g├®n├®raux).
Exemples┬Ā:
MOV AX, 5
MOV ES, DX
MOV AL, [Variable1] ; Copie un octet, car AL contient 8 bits
MOV [Variable2], DS ; Copie un word car DS contient 16 bits
MOV word ptr [Variable3], 12 ; Ici, on sp├®cifie que la variable est un word
IV-C-3. L'instruction XCHG (┬½ Exchange ┬╗)▲
Syntaxe┬Ā: XCHG Destination, Source
Description┬Ā: ├ēchange les contenus de Source et de Destination.
Mouvements autoris├®s┬Ā:
XCHG Registre g├®n├®ral, Registre g├®n├®ral
XCHG Registre g├®n├®ral, M├®moire
XCHG M├®moire, Registre g├®n├®ral
IV-C-4. L'instruction JMP (┬½ Jump ┬╗)▲
Syntaxe┬Ā: JMP MonLabel
Description┬Ā: Saute ├Ā l'instruction point├®e par MonLabel.
IV-C-5. L'op├®rateur CMP (┬½ Compare ┬╗)▲
Syntaxe┬Ā: CMP Destination, Source
Description┬Ā: Cet op├®rateur sert ├Ā comparer deux nombres┬Ā: Source et Destination. C'est le registre des indicateurs qui contient les r├®sultats de la comparaison. Ni Source ni Destination ne sont modifi├®s.
Indicateurs affect├®s┬Ā: AF, CF, OF, PF, SF, ZF
Remarque┬Ā: Cet op├®rateur effectue en fait une soustraction, mais contrairement ├Ā SUB, le r├®sultat n'est pas sauvegard├®.
Le programme doit pouvoir r├®agir en fonction des r├®sultats de la comparaison. Pour cela, on utilise les sauts conditionnels (voir ci-dessous).
IV-C-6. Les instructions de saut conditionnel▲
Les sauts conditionnels sont terriblement importants, car ils permettent au programme de faire des choix en fonction des donn├®es.
Un saut conditionnel n'est effectu├® qu'├Ā certaines conditions portant sur les flags (par exemple┬Ā: CF┬Ā=┬Ā1 ou ZF┬Ā=┬Ā0).
Certains mn├®moniques de sauts conditionnels sont totalement ├®quivalents, c'est-├Ā-dire qu'ils repr├®sentent le m├¬me opcode hexad├®cimal. C'est pour aider le programmeur qu'ils existent parfois sous plusieurs formes.
IV-C-6-a. les sauts de comparaison▲
- JE (┬½┬ĀJump if Equal┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si ZF┬Ā=┬Ā1. Rappelez-vous que ce flag est ├Ā 1 si et seulement si le r├®sultat de l'op├®ration pr├®c├®dente vaut z├®ro. Comme CMP r├®alise une soustraction, on utilise g├®n├®ralement JE pour savoir si deux nombres sont ├®gaux.
Exemple┬Ā:

Mn├®monique ├®quivalent┬Ā: JZ (┬½┬ĀJump if Zero┬Ā┬╗)
- JG (┬½┬ĀJump if Greater┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si ZF┬Ā=┬Ā0 et SF┬Ā=┬ĀOF. On l'utilise en arithm├®tique sign├®e pour savoir si un nombre est sup├®rieur ├Ā un autre.
Exemple:

Mn├®monique ├®quivalent┬Ā: JNLE (┬½┬ĀJump if Not Less Or Equal┬Ā┬╗)
- JGE (┬½┬ĀJump if Greater or Equal┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si SF┬Ā=┬ĀOF. On l'utilise en arithm├®tique sign├®e pour savoir si un nombre est sup├®rieur ou ├®gal ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNL (┬½┬ĀJump if Not Less┬Ā┬╗)
- JL (┬½┬ĀJump if Less┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si SF <> OF. On l'utilise en arithm├®tique sign├®e pour savoir si un nombre est inf├®rieur ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNGE (┬½┬ĀJump if Not Greater Or Equal┬Ā┬╗)
- JLE (┬½┬ĀJump if Less Or Equal┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si SF <> OF ou ZF┬Ā=┬Ā1. On l'utilise en arithm├®tique sign├®e pour savoir si un nombre est inf├®rieur ou ├®gal ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNG (┬½┬ĀJump if Not Greater┬Ā┬╗)
- JA (┬½┬ĀJump if Above┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si ZF┬Ā=┬Ā0 et CF┬Ā=┬Ā0. On l'utilise en arithm├®tique non sign├®e pour savoir si un nombre est sup├®rieur ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNBE (┬½┬ĀJump if Not Below Or Equal┬Ā┬╗)
- JAE (┬½┬ĀJump if Above or Equal┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CF┬Ā=┬Ā0. On l'utilise en arithm├®tique non sign├®e pour savoir si un nombre est sup├®rieur ou ├®gal ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNB (┬½┬ĀJump if Not Below┬Ā┬╗)
- JB (┬½┬ĀJump if Below┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CF┬Ā=┬Ā1. On l'utilise en arithm├®tique non sign├®e pour savoir si un nombre est inf├®rieur ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNAE (┬½┬ĀJump if Not Above Or Equal┬Ā┬╗)
- JBE (┬½┬ĀJump if Below or Equal┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CF┬Ā=┬Ā1 ou ZF┬Ā=┬Ā1. On l'utilise en arithm├®tique non sign├®e pour savoir si un nombre est inf├®rieur ou ├®gal ├Ā un autre.
Mn├®monique ├®quivalent┬Ā: JNA (┬½┬ĀJump if Not Above┬Ā┬╗)
IV-C-6-a-i. les sauts de test sur les flags▲
Ces instructions testent un flag unique et ex├®cutent ou non le saut selon la valeur de ce flag.
- JC (┬½┬ĀJump if Carry┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CF┬Ā=┬Ā1.
Remarques┬Ā: Ce mn├®monique correspond au m├¬me opcode que JB. Il est souvent employ├® pour v├®rifier que l'appel d'une interruption n'a pas d├®clench├® d'erreur.
Exemple┬Ā:

Si l'appel de la fonction 3Eh de l'interruption 21H se solde par une erreur, alors la CF vaudra 1 et le saut sera accompli. Dans le cas oppos├®, l'ex├®cution continuera normalement de mani├©re lin├®aire.
- JNC (┬½┬ĀJump if not Carry┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CF┬Ā=┬Ā0.
- JZ (┬½┬ĀJump if Zero┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si ZF┬Ā=┬Ā1. Ce mn├®monique correspond au m├¬me opcode que JE.
- JNZ (┬½┬ĀJump if not Zero┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si ZF┬Ā=┬Ā0. Ce mn├®monique correspond au m├¬me opcode que JNE.
- JS (┬½┬ĀJump if Sign┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si SF┬Ā=┬Ā1.
- JNS (┬½┬ĀJump if not Sign┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si SF┬Ā=┬Ā0.
- JO (┬½┬ĀJump if Overflow┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si OF┬Ā=┬Ā1.
- JNO (┬½┬ĀJump if not Overflow┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si OF┬Ā=┬Ā0.
- JP (┬½┬ĀJump if Parity┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si PF┬Ā=┬Ā1.
- JNP (┬½┬ĀJump if not Parity┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si PF┬Ā=┬Ā0.
IV-C-6-a-ii. le saut de test sur le registre CX▲
JCXZ (┬½┬ĀJump if CX┬Ā=┬ĀZero┬Ā┬╗) fait un saut au label sp├®cifi├® si et seulement si CX┬Ā=┬Ā0.
IV-C-6-b. Les instructions arithm├®tiques▲
IV-C-6-b-i. L'instruction INC (┬½ Increment ┬╗)▲
Syntaxe ┬Ā: INC┬Ā Destination
Description ┬Ā: Incr├®mente┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, OF, PF, SF, ZF
Exemple ┬Ā: INC CL
IV-C-6-b-ii. L'instruction ADD (┬½ Addition ┬╗)▲
Syntaxe ┬Ā: ADD┬Ā Destination ,┬Ā Source
Description ┬Ā: Ajoute┬Ā Source ┬Ā├Ā┬Ā Destination.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
Exemple ┬Ā: ADD byte ptr [ VARIABLE ┬Ā+ DI],┬Ā 5
IV-C-6-b-iii. L'instruction ADC (┬½ Add with Carry ┬╗)▲
Syntaxe ┬Ā: ADC┬Ā Destination ,┬Ā Source
Description ┬Ā: Ajoute ( Source ┬Ā+ CF) ├Ā┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-b-iv. L'instruction DEC (┬½ Decrement ┬╗)▲
Syntaxe ┬Ā: DEC┬Ā Destination
Description ┬Ā: D├®cr├®mente┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, OF, PF, SF, ZF
IV-C-6-b-v. L'instruction SUB (┬½ Substract ┬╗)▲
Syntaxe ┬Ā: SUB┬Ā Destination ,┬Ā Source
Description ┬Ā: Soustrait┬Ā Source ┬Ā├Ā┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-b-vi. L'instruction SBB (┬½ Substract with Borrow ┬╗)▲
Syntaxe ┬Ā: SBB┬Ā Destination ,┬Ā Source
Description ┬Ā: Soustrait ( Source ┬Ā+ CF) ├Ā┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-b-vii. L'instruction MUL (┬½ Multiply ┬╗)▲
Syntaxe ┬Ā: MUL┬Ā Source
Description ┬Ā: Effectue une multiplication d'entiers┬Ā non sign├®s .
- Si┬Ā Source ┬Āest un┬Ā octet ┬Ā: AL est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans AX.
- Si┬Ā Source ┬Āest un┬Ā mot ┬Ā: AX est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans DX:AX.
- Si┬Ā Source ┬Āest un┬Ā double-mot ┬Ā: EAX est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans EDX:EAX.
Indicateurs affect├®s ┬Ā: CF, OF
Remarque ┬Ā:┬Ā Source ne peut ├¬tre une valeur imm├®diate.
Exemples ┬Ā: MUL CX
MUL byte ptr [ TOTO ]
IV-C-6-b-viii. L'instruction IMUL (┬½ Integer Multiply ┬╗)▲
Syntaxe ┬Ā: IMUL┬Ā Source
IMUL┬Ā Destination ,┬Ā Source
IMUL┬Ā Destination ,┬Ā Source ,┬Ā Valeur
Description ┬Ā: Effectue une multiplication d'entiers┬Ā sign├®s .
IMUL┬Ā Source ┬Ā:
- Si┬Ā Source ┬Āest un┬Ā octet ┬Ā: AL est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans AX.
- Si┬Ā Source ┬Āest un┬Ā mot ┬Ā: AX est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans DX:AX.
- Si┬Ā Source ┬Āest un┬Ā double-mot ┬Ā: EAX est multipli├® par┬Ā Source ┬Āet le r├®sultat est plac├® dans EDX:EAX.
IMUL┬Ā Destination ,┬Ā Source ┬Ā: Multiplie┬Ā Destination ┬Āpar┬Ā Source ┬Āet place le r├®sultat dans┬Ā Destination .
IMUL┬Ā Destination ,┬Ā Source ,┬Ā Valeur ┬Ā: Multiplie┬Ā Source ┬Āpar┬Ā Valeur ┬Āet place le r├®sultat dans┬Ā Destination .
Indicateurs affect├®s ┬Ā: CF, OF
IV-C-6-b-ix. L'instruction DIV (┬½ Divide ┬╗)▲
Syntaxe ┬Ā: DIV┬Ā Source
Description ┬Ā: Effectue une division euclidienne d'entiers┬Ā non sign├®s .
- Si┬Ā Source ┬Āest un┬Ā octet ┬Ā: AX est divis├® par┬Ā Source , le quotient est plac├® dans AL et le reste dans AH.
- Si┬Ā Source ┬Āest un┬Ā mot ┬Ā: DX:AX est divis├® par┬Ā Source , le quotient est plac├® dans AX et le reste dans DX.
- Si┬Ā Source ┬Āest un┬Ā double-mot ┬Ā: EDX:EAX est divis├® par┬Ā Source , le quotient est plac├® dans EAX et le reste dans EDX.
Indicateurs affect├®s ┬Ā: AF, OF, PF, SF, ZF
Remarque ┬Ā:┬Ā Source ne peut ├¬tre une valeur imm├®diate.
IV-C-6-b-x. L'instruction IDIV (┬½ Integer Divide ┬╗)▲
Syntaxe ┬Ā: IDIV┬Ā Source
Description ┬Ā: Effectue une division euclidienne d'entiers┬Ā sign├®s .
- Si┬Ā Source ┬Āest un┬Ā octet ┬Ā: AX est divis├® par┬Ā Source , le quotient est plac├® dans AL et le reste dans AH.
- Si┬Ā Source ┬Āest un┬Ā mot ┬Ā: DX:AX est divis├® par┬Ā Source , le quotient est plac├® dans AX et le reste dans DX.
- Si┬Ā Source ┬Āest un┬Ā double-mot ┬Ā: EDX:EAX est divis├® par┬Ā Source , le quotient est plac├® dans EAX et le reste dans EDX.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-b-xi. L'instruction NEG (┬½ Negation ┬╗)▲
Syntaxe ┬Ā: NEG┬Ā Destination
Description ┬Ā: Forme le compl├®ment ├Ā 2 de┬Ā Destination , i.e. prend l'oppos├® de┬Ā Destination .
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
Remarque ┬Ā: ├Ć ne pas confondre avec NOT, qui forme le compl├®ment ├Ā 1.
IV-C-6-c. Les instructions logiques▲
IV-C-6-c-i. L'instruction NOT (┬½ Logical NOT ┬╗)▲
Syntaxe ┬Ā: NOT┬Ā Destination
Description ┬Ā: Effectue un NON logique bit ├Ā bit sur┬Ā Destination ┬Ā(i.e. chaque bit de┬Ā Destination est invers├®).
IV-C-6-c-ii. L'instruction OR (┬½ Logical OR ┬╗)▲
Syntaxe ┬Ā: OR┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue un OU logique inclusif bit ├Ā bit entre┬Ā Destination ┬Āet┬Ā Source . Le r├®sultat est stock├® dans┬Ā Destination .
Indicateurs affect├®s ┬Ā: CF, OF, PF, SF, ZF
Remarque
┬Ā: Afin d'optimiser la taille et les performances du programme, on peut utiliser l'instruction ŌĆ£OR AX, AXŌĆØ ├Ā la place de ŌĆ£CMP AX, 0ŌĆØ.┬Ā
En effet, un OU bit ├Ā bit entre deux nombres identiques ne modifie pas┬Ā
Destination
┬Āet est ex├®cut├® ┬½┬Āinfiniment┬Ā┬╗ plus rapidement qu'une soustraction. Comme les flags sont affect├®s, les sauts conditionnels sont possibles.
IV-C-6-c-iii. L'instruction AND (┬½ Logical AND ┬╗)▲
Syntaxe ┬Ā: AND┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue un ET logique bit ├Ā bit entre┬Ā Destination ┬Āet┬Ā Source . Le r├®sultat est stock├® dans┬Ā Destination .
Indicateurs affect├®s ┬Ā: CF, OF, PF, SF, ZF
IV-C-6-c-iv. L'instruction TEST (┬½ Test for bit pattern ┬╗)▲
Syntaxe ┬Ā: TEST┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue un ET logique bit ├Ā bit entre┬Ā Destination ┬Āet┬Ā Source . Le r├®sultat n'est pas conserv├®, donc┬Ā Destination ┬Ān'est pas modifi├®. Seuls les flags sont affect├®s.
Cet op├®rateur est souvent utilis├® pour tester certains bits de┬Ā Destination .
Indicateurs affect├®s ┬Ā: CF, OF, PF, SF, ZF
Exemple ┬Ā:
IV-C-6-c-v. L'instruction XOR (┬½ Exclusive logical OR ┬╗)▲
Syntaxe ┬Ā: XOR┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue un OU logique exclusif bit ├Ā bit entre┬Ā Destination ┬Āet┬Ā Source . Le r├®sultat est stock├® dans┬Ā Destination .
Indicateurs affect├®s ┬Ā: CF, OF, PF, SF, ZF
Remarque ┬Ā: Pour remettre un registre ├Ā z├®ro, il est pr├®f├®rable de faire ŌĆ£XOR AX, AXŌĆØ que ŌĆ£MOV AX, 0ŌĆØ. En effet, le r├®sultat est le m├¬me, mais la taille et surtout la vitesse d'ex├®cution de l'instruction sont tr├©s largement optimis├®es.
IV-C-6-c-vi. L'instruction SHL (┬½ Shift logical Left ┬╗)▲
Syntaxe ┬Ā: SHL┬Ā Destination ,┬Ā Source
Description ┬Ā: D├®cale les bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la gauche. Les bits les plus ├Ā droite sont remplac├®s par des z├®ros.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
Exemple┬Ā: SHL AX,┬Ā4┬Ā;permet de multiplier par 16 de fa├¦on infiniment plus rapide que MUL
Mn├®monique ├®quivalent┬Ā: SAL (┬½┬Ā Shift Arithmetical Left ┬Ā┬╗)
IV-C-6-c-vii. L'instruction SHR (┬½ Shift logical Right ┬╗)▲
Syntaxe ┬Ā: SHR┬Ā Destination ,┬Ā Source
Description ┬Ā: D├®cale les bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la droite. Les bits les plus ├Ā gauche sont remplac├®s par des z├®ros.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
Mn├®monique ├®quivalent┬Ā: SAR (┬½┬Ā Shift Arithmetical Right ┬Ā┬╗)
IV-C-6-c-viii. L'instruction ROL (┬½ Rotate Left ┬╗)▲
Syntaxe ┬Ā: ROL┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue une rotation des bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la gauche. Le dernier bit ├Ā ├¬tre sorti ├Ā gauche et ├Ā ├¬tre rentr├® ├Ā droite est plac├® dans CF. OF est mis ├Ā 1 si et seulement si le signe de┬Ā Destination ┬Āa chang├®.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-c-ix. L'instruction ROR (┬½ Rotate Right ┬╗)▲
Syntaxe ┬Ā: ROR┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue une rotation des bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la droite. Le dernier bit ├Ā ├¬tre sorti ├Ā droite et ├Ā ├¬tre rentr├® ├Ā gauche est plac├® dans CF. OF est mis ├Ā 1 si et seulement si le signe de┬Ā Destination ┬Āa chang├®.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-c-x. L'instruction RCL (┬½ Rotate through Carry Left ┬╗)▲
Syntaxe ┬Ā: RCL┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue une rotation des bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la gauche. CF est utilis├® comme interm├®diaire┬Ā: chaque bit qui sort ├Ā gauche est plac├® dans CF, et le contenu de CF est ensuite r├®ins├®r├® ├Ā droite. OF est mis ├Ā 1 si et seulement si le signe de┬Ā Destination ┬Āa chang├®.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-c-xi. L'instruction RCR (┬½ Rotate through Carry Right ┬╗)▲
Syntaxe ┬Ā: RCR┬Ā Destination ,┬Ā Source
Description ┬Ā: Effectue une rotation des bits de┬Ā Destination ┬Āde┬Ā Source ┬Āpositions vers la droite. CF est utilis├® comme interm├®diaire┬Ā: chaque bit qui sort ├Ā droite est plac├® dans CF, et le contenu de CF est ensuite r├®ins├®r├® ├Ā gauche. OF est mis ├Ā 1 si et seulement si le signe de┬Ā Destination ┬Āa chang├®.
Indicateurs affect├®s ┬Ā: AF, CF, OF, PF, SF, ZF
IV-C-6-d. Les instructions de manipulation des flags▲
IV-C-6-d-i. L'instruction CLC (┬½ Clear Carry flag ┬╗)▲
Syntaxe┬Ā: CLC
Description┬Ā: Met CF ├Ā 0.
Indicateurs affect├®s┬Ā: CF
IV-C-6-d-ii. L'instruction STC (┬½ Set Carry flag ┬╗)▲
Syntaxe┬Ā: STC
Description┬Ā: Met CF ├Ā 1.
Indicateurs affect├®s┬Ā: CF
IV-C-6-d-iii. L'instruction CLD (┬½ Clear Direction flag ┬╗)▲
Syntaxe┬Ā: CLD
Description┬Ā: Met DF ├Ā 0.
Indicateurs affect├®s┬Ā: DF
IV-C-6-d-iv. L'instruction STD (┬½ Set Direction flag ┬╗)▲
Syntaxe┬Ā: STD
Description┬Ā: Met DF ├Ā 1.
Indicateurs affect├®s┬Ā: DF
IV-C-6-d-v. L'instruction CLI (┬½ Clear Interrupt flag ┬╗)▲
Syntaxe┬Ā: CLI
Description┬Ā: Met IF ├Ā 0.
Indicateurs affect├®s┬Ā: IF
IV-C-6-d-vi. L'instruction STI (┬½ Set Interrupt flag ┬╗)▲
Syntaxe┬Ā: STI
Description┬Ā: Met IF ├Ā 1.
Indicateurs affect├®s┬Ā: IF
IV-C-6-d-vii. L'instruction CMC (┬½ Complement Carry flag ┬╗)▲
Syntaxe┬Ā: CMC
Description┬Ā: Inverse CF.
Indicateurs affect├®s┬Ā: CF
IV-C-6-d-viii. L'instruction LAHF (┬½ Load AH from Flags ┬╗)▲
Syntaxe┬Ā: LAHF
Description┬Ā: Charge dans AH l'octet de poids faible du registre des indicateurs.
IV-C-6-d-ix. L'instruction SAHF (┬½ Store AH into Flags ┬╗)▲
Syntaxe┬Ā: SAHF
Description┬Ā: Stocke les bits de AH dans le registre des indicateurs.
IV-C-6-e. Les instructions de gestion de la pile▲
IV-C-6-e-i. L'instruction PUSH (┬½ Push Word onto Stack ┬╗)▲
Syntaxe┬Ā: PUSH┬ĀSource
Description┬Ā: Empile le mot┬ĀSource. SP est d├®cr├®ment├® de 2.
Remarques┬Ā:┬ĀSource┬Āne peut ├¬tre une valeur imm├®diate. Il est possible d'abr├®ger votre code source en ├®crivant par exemple ŌĆ£PUSH AX BX BPŌĆØ. Le compilateur ├®crira alors trois fois l'instruction PUSH du langage machine. Il est possible ├®galement d'empiler des doubles-mots.
IV-C-6-e-ii. L'instruction POP (┬½ Pop Word off Stack ┬╗)▲
Syntaxe┬Ā: POP┬ĀDestination
Description┬Ā: D├®pile le mot qui se trouve au sommet de la pile et le place dans┬ĀDestination. SP est incr├®ment├® de 2.
IV-C-6-e-iii. L'instruction PUSHF (┬½ Push Flags onto Stack ┬╗)▲
Syntaxe┬Ā: PUSHF
Description┬Ā: Empile le registre des indicateurs. SP est d├®cr├®ment├® de 2.
Remarque┬Ā: PUSHFD empile le registre des indicateurs cod├® sur 32 bits.
IV-C-6-e-iv. L'instruction POPF (┬½ Pop Flags off Stack ┬╗)▲
Syntaxe┬Ā: POPF
Description┬Ā: D├®pile le mot qui se trouve au sommet de la pile et le place dans le registre des indicateurs. SP est incr├®ment├® de 2.
Indicateurs affect├®s┬Ā: Tous
Remarque┬Ā: POPFD est utilis├® pour un registre des indicateurs cod├® sur 32 bits.
IV-C-6-e-v. L'instruction PUSHA (┬½ Push All registers onto Stack ┬╗)▲
Syntaxe┬Ā: PUSHA
Description┬Ā: Empile AX, BX, CX, DX, BP, SI, DI et SP.
Remarque┬Ā: PUSHAD est utilis├® pour des registres de 32 bits.
IV-C-6-e-vi. L'instruction POPA (┬½ Pop All registers off Stack ┬╗)▲
Syntaxe┬Ā: POPA
Description┬Ā: Restaure AX, BX, CX, DX, BP, SI, DI et SP ├Ā partir de la pile.
Remarque┬Ā: POPAD est utilis├® pour des registres de 32 bits.
IV-C-6-f. Les instructions de gestion des cha├«nes d'octets▲
IV-C-6-f-i. L'instruction MOVSB (┬½ Move String Byte ┬╗)▲
Syntaxe┬Ā: MOVSB
Description┬Ā: Copie l'octet adress├® par DS:SI ├Ā l'adresse ES:DI. Si DF =┬Ā0, alors DI et SI sont ensuite incr├®ment├®s, sinon ils sont d├®cr├®ment├®s.
Remarque┬Ā: Pour copier plusieurs octets, faire REP MOVSB (┬½┬ĀRepeat Move String Byte┬Ā┬╗). Le nombre d'octets ├Ā copier doit ├¬tre transmis dans CX de m├¬me que pour un LOOP.
Exemple┬Ā:

IV-C-6-f-ii. L'instruction SCASB (┬½ Scan String Byte ┬╗)▲
Syntaxe┬Ā: SCASB
Description┬Ā: Compare l'octet adress├® par ES:DI avec AL. Les r├®sultats sont plac├®s dans le registre des indicateurs. Si DF =┬Ā0, alors DI est ensuite incr├®ment├®, sinon il est d├®cr├®ment├®.
Remarques┬Ā: Pour comparer plusieurs octets, faire ŌĆ£REP SCASBŌĆØ ou ŌĆ£REPE SCASBŌĆØ (┬½┬ĀRepeat until Egal┬Ā┬╗), ou encore ŌĆ£REPZ SCASBŌĆØ (┬½┬ĀRepeat until Zero┬Ā┬╗). Ces trois pr├®fixes sont ├®quivalents.┬Ā
Le nombre d'octets ├Ā comparer doit ├¬tre transmis dans CX. La boucle ainsi cr├®├®e s'arr├¬te si CX =┬Ā0 ou si le caract├©re point├® par ES:DI est le m├¬me que celui contenu dans AL (i.e. si ZF =┬Ā1). On peut ainsi rechercher un caract├©re dans une cha├«ne.┬Ā
Pour r├®p├®ter au contraire la comparaison┬Ājusqu'├Ā ce que┬ĀZF =┬Ā0, c'est-├Ā-dire jusqu'├Ā ce que AL et le caract├©re adress├® par ES:DI┬Ādiff├©rent, utiliser REPNE ou REPNZ.
Exemple┬Ā:

IV-C-6-f-iii. L'instruction LODSB (┬½ Load String Byte ┬╗)▲
Syntaxe┬Ā: LODSB
Description┬Ā: Charge dans AL l'octet adress├® par DS:SI. Si DF =┬Ā0, alors SI est ensuite incr├®ment├®, sinon il est d├®cr├®ment├®.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour MOVSB.
Syntaxe┬Ā: STOSB
Description┬Ā: Stocke le contenu de AL dans l'octet adress├® par ES:DI. Si DF =┬Ā0, alors DI est ensuite incr├®ment├®, sinon il est d├®cr├®ment├®.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour LODSB.
Syntaxe┬Ā: CMPSB
Description┬Ā: Compare l'octet adress├® par DS:SI et celui adress├® par ES:DI. Si DF =┬Ā0, alors SI et DI sont ensuite incr├®ment├®s, sinon ils sont d├®cr├®ment├®s.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour SCASB.
IV-C-6-g. Les instructions de gestion des cha├«nes de mots▲
Ce sont les m├¬mes que les pr├®c├®dentes, hormis qu'elles traitent des mots et non des octets et que leur nom se termine par un ŌĆśW' au lieu du ŌĆśB'.
IV-C-6-g-i. L'instruction MOVSW (┬½ Move String Word ┬╗)▲
Syntaxe┬Ā: MOVSW
Description┬Ā: Copie le mot adress├® par DS:SI ├Ā l'adresse ES:DI. Si DF =┬Ā0, alors DI et SI sont ensuite incr├®ment├®s de 2, sinon ils sont d├®cr├®ment├®s de 2.
Remarque┬Ā: Pour copier plusieurs mots, faire ŌĆ£REP MOVSWŌĆØ. Le nombre de mots ├Ā copier doit ├¬tre transmis dans CX.
IV-C-6-g-ii. L'instruction SCASW (┬½ Scan String Word ┬╗)▲
Syntaxe┬Ā: SCASW
Description┬Ā: Compare le mot adress├® par ES:DI avec AX. Les r├®sultats sont plac├®s dans le registre des indicateurs. Si DF =┬Ā0, alors DI est ensuite incr├®ment├® de 2, sinon il est d├®cr├®ment├® de 2.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour SCASB.
IV-C-6-g-iii. L'instruction LODSW (┬½ Load String Word ┬╗)▲
Syntaxe┬Ā: LODSW
Description┬Ā: Charge dans AX le mot adress├® par DS:SI. Si DF =┬Ā0, alors SI est ensuite incr├®ment├® de 2, sinon il est d├®cr├®ment├® de 2.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour LODSB.
IV-C-6-g-iv. L'instruction STOSW (┬½ Store String Word ┬╗)▲
Syntaxe┬Ā: STOSW
Description┬Ā: Stocke le contenu de AX dans le mot adress├® par ES:DI. Si DF =┬Ā0, alors DI est ensuite incr├®ment├® de 2, sinon il est d├®cr├®ment├® de 2.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour STOSB.
IV-C-6-g-v. L'instruction CMPSW (┬½ Compare String Word ┬╗)▲
Syntaxe┬Ā: CMPSW
Description┬Ā: Compare le mot adress├® par DS:SI et celui adress├® par ES:DI. Si DF =┬Ā0, alors SI et DI sont ensuite incr├®ment├®s de 2, sinon ils sont d├®cr├®ment├®s de 2.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour CMPSB.
IV-C-6-h. Les instructions de gestion des cha├«nes de doubles-mots▲
Elles traitent des doubles-mots et leur nom se termine par un ŌĆśD'.
IV-C-6-h-i. L'instruction MOVSD (┬½ Move String Double Word ┬╗)▲
Syntaxe┬Ā: MOVSD
Description┬Ā: Copie le double-mot adress├® par DS:SI ├Ā l'adresse ES:DI. Si DF =┬Ā0, alors DI et SI sont ensuite incr├®ment├®s de 4, sinon ils sont d├®cr├®ment├®s de 4.
Remarque┬Ā: Pour copier plusieurs doubles-mots, faire ŌĆ£REP MOVSDŌĆØ. Le nombre de doubles-mots ├Ā copier doit ├¬tre transmis dans CX.
IV-C-6-h-ii. L'instruction SCASD (┬½ Scan String Double Word ┬╗)▲
Syntaxe┬Ā: SCASD
Description┬Ā: Compare le double-mot adress├® par ES:DI avec EAX. Les r├®sultats sont plac├®s dans le registre des indicateurs. Si DF =┬Ā0, alors DI est ensuite incr├®ment├® de 4, sinon il est d├®cr├®ment├® de 4.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour SCASB.
IV-C-6-h-iii. L'instruction LODSD (┬½ Load String Double Word ┬╗)▲
Syntaxe┬Ā: LODSD
Description┬Ā: Charge dans EAX le double-mot adress├® par DS:SI. Si DF =┬Ā0, alors SI est ensuite incr├®ment├® de 4, sinon il est d├®cr├®ment├® de 4.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour LODSB.
IV-C-6-h-iv. L'instruction STOSD (┬½ Store String Double Word ┬╗)▲
Syntaxe┬Ā: STOSD
Description┬Ā: Stocke le contenu de EAX dans le double-mot adress├® par ES:DI. Si DF =┬Ā0, alors DI est ensuite incr├®ment├® de 4, sinon il est d├®cr├®ment├® de 4.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour STOSB.
IV-C-6-h-v. L'instruction CMPSD (┬½ Compare String Double Word ┬╗)▲
Syntaxe┬Ā: CMPSD
Description┬Ā: Compare le double-mot adress├® par DS:SI et celui adress├® par ES:DI. Si DF =┬Ā0, alors SI et DI sont ensuite incr├®ment├®s de 4, sinon ils sont d├®cr├®ment├®s de 4.
Remarque┬Ā: Possibilit├® d'utiliser les pr├®fixes de r├®p├®tition, de m├¬me que pour CMPSB.
IV-C-6-i. Les instructions d'appel▲
IV-C-6-i-i. L'instruction CALL (┬½ Procedure Call ┬╗)▲
Syntaxe┬Ā: CALL┬ĀMaProc
Description┬Ā: Appel de proc├®dure. Si┬ĀMaProc┬Āse trouve dans un segment ext├®rieur, le processeur empile CS. Ensuite, dans tous les cas, il empile IP et fait un saut ├Ā l'├®tiquette┬ĀMaProc.
IV-C-6-i-ii. L'instruction RET (ou RETN)▲
Syntaxe┬Ā: RET
Description┬Ā: Retour de proc├®dure se trouvant ├Ā l'int├®rieur du segment (NEAR). Un mot est d├®pil├® et plac├® dans IP. Le contr├┤le retourne donc ├Ā la proc├®dure appelante.
IV-C-6-i-iii. L'instruction RETF▲
Syntaxe┬Ā: RETF
Description┬Ā: Retour de proc├®dure se trouvant ├Ā l'ext├®rieur du segment (FAR). Deux mots sont d├®pil├®s et plac├®s dans CS:IP. Le contr├┤le retourne donc ├Ā la proc├®dure appelante.
IV-C-6-j. Les instructions de boucle▲
IV-C-6-j-i. L'instruction LOOP▲
Syntaxe┬Ā: LOOP┬ĀMonLabel
Description┬Ā: D├®cr├®mente CX, puis, si CX <>┬Ā0, fait un saut ├Ā┬ĀMonLabel.
IV-C-6-j-ii. L'instruction LOOPE (┬½ Loop while Equal ┬╗)▲
Syntaxe┬Ā: LOOPE┬ĀMonLabel
Description┬Ā: D├®cr├®mente CX, puis, si CX <>┬Ā0 et ZF =┬Ā1, fait un saut ├Ā┬ĀMonLabel.
Mn├®monique ├®quivalent┬Ā: LOOPZ
IV-C-6-j-iii. L'instruction LOOPNE (┬½ Loop while not Equal ┬╗)▲
Syntaxe┬Ā: LOOPNE┬ĀMonLabel
Description┬Ā: D├®cr├®mente CX, puis, si CX <>┬Ā0 et ZF =┬Ā0, fait un saut ├Ā┬ĀMonLabel.
Mn├®monique ├®quivalent┬Ā: LOOPNZ
IV-C-6-k. Les instructions d'adressage▲
IV-C-6-k-i. L'instruction LEA (┬½ Load effective address ┬╗)▲
Syntaxe┬Ā: LEA┬ĀDestination,┬ĀSource
Description┬Ā: Charge l'offset de la source dans le registre┬ĀDestination.
Exemple┬Ā: LEA BP, word ptr [BP +┬ĀTOTO]
IV-C-6-k-ii. L'instruction LDS (┬½ Load pointer using DS ┬╗)▲
Syntaxe┬Ā: LDS┬ĀDestination,┬ĀSource
Description┬Ā: Transf├©re dans DS:Destination┬Āle contenu de la m├®moire adress├®e par┬ĀSource.
IV-C-6-k-iii. L'instruction LES (┬½ Load pointer using ES ┬╗)▲
Syntaxe┬Ā: LES┬ĀDestination,┬ĀSource
Description┬Ā: Transf├©re dans ES:Destination┬Āle contenu de la m├®moire adress├®e par┬ĀSource.
IV-C-6-l. Les instructions de conversion arithm├®tique▲
Remarque pr├®liminaire┬Ā: Nous n'expliciterons pas toutes ces instructions.
IV-C-6-l-i. L'instruction AAA (┬½ ASCII Adjust for Addition ┬╗)▲
IV-C-6-l-ii. L'instruction AAD (┬½ ASCII Adjust for Division ┬╗)▲
IV-C-6-l-iii. L'instruction AAM (┬½ ASCII Adjust for Multiplication ┬╗)▲
IV-C-6-l-iv. L'instruction AAS (┬½ ASCII Adjust for Substraction ┬╗)▲
IV-C-6-l-v. L'instruction CBW (┬½ Convert Byte to Word ┬╗)▲
Syntaxe┬Ā: CBW
Description┬Ā: Convertit l'octet┬Āsign├®┬Āstock├® dans AL en un mot (sign├®) stock├® dans AX. Ainsi, si AL est n├®gatif, AH sera rempli de 1 binaires, sinon, AH sera mis ├Ā 0.
IV-C-6-l-vi. L'instruction CWD (┬½ Convert Word to Double Word ┬╗)▲
Syntaxe┬Ā: CWD
Description┬Ā: Convertit le mot┬Āsign├®┬Āstock├® dans AX en un double-mot (sign├®) stock├® dans DX:AX. Ainsi, si AX est n├®gatif, DX sera rempli de 1 binaires, sinon DX sera mis ├Ā 0.
IV-C-6-l-vii. L'instruction DAA (┬½ Decimal Adjust for Addition ┬╗)▲
IV-C-6-l-viii. L'instruction DAS (┬½ Decimal Adjust for Substraction ┬╗)▲
IV-C-6-l-ix. L'instruction MOVSX (┬½ Move with Sign Extend ┬╗)▲
Syntaxe┬Ā: MOVSX┬ĀDestination,┬ĀSource
Description┬Ā: D├®place le contenu┬Āsign├®┬Ād'un registre de 8 bits dans un registre de 16 bits, ou bien d├®place le contenu sign├® d'un registre de 16 bits dans un registre de 32 bits. Si┬ĀSource┬Āest n├®gatif, la partie haute de┬ĀDestination┬Āsera remplie de 1 binaires, sinon elle sera remplie de 0.
IV-C-6-l-x. L'instruction MOVZX (┬½ Move with Zero Extend ┬╗)▲
Syntaxe┬Ā: MOVZX┬ĀDestination,┬ĀSource
Description┬Ā: D├®place le contenu┬Ānon sign├®┬Ād'un registre de 8 bits dans un registre de 16 bits, ou bien d├®place le contenu sign├® d'un registre de 16 bits dans un registre de 32 bits. La partie haute de Destination┬Āsera donc mise ├Ā 0.
IV-C-6-l-xi. L'instruction XLAT (┬½ Translate ┬╗)▲
IV-C-6-m. Les instructions d'entr├®e-sortie▲
IV-C-6-m-i. L'instruction IN (┬½ Input from port ┬╗)▲
Syntaxe┬Ā: IN┬ĀDestination,┬ĀPort
Description┬Ā: Charge un octet ou un mot depuis un port d'entr├®e-sortie dans AL ou AX.┬ĀPort┬Āpeut ├¬tre DX ou bien une constante de 8 bits.
IV-C-6-m-ii. L'instruction OUT (┬½ Output to port ┬╗)▲
Syntaxe┬Ā: OUT┬ĀPort,┬ĀSource
Description┬Ā: ├ēcrit dans Port la valeur contenue dans Source. Source ne peut ├¬tre que AL ou AX. Port est une constante ou bien DX.
V. QUATRI├łME PARTIE▲
Remarque pr├®liminaire┬Ā: Cette partie pr├®sente quelques-unes des interruptions du DOS qui servent ├Ā manier les fichiers d'un disque. Nous la conclurons par l'├®tude d'un exemple de programme qui crypte un fichier choisi par l'utilisateur.
V-A. LECTURE ET ├ēCRITURE DE FICHIERS AVEC LES HANDLES▲
Sous DOS, il existe deux m├®thodes pour acc├®der aux fichiers et pour chacune d'elles un lot d'interruptions sp├®cifiques. La premi├©re est la m├®thode des FCB (┬½┬ĀFile contol block┬Ā┬╗). Elle est rarement utilis├®e, aussi ne l'aborderons-nous pas. Nous ├®tudierons le principe de la m├®thode des ┬½┬Āhandles┬Ā┬╗.
Pour lire ou ├®crire des donn├®es dans un fichier, il est n├®cessaire de l'ouvrir, c'est-├Ā-dire de le charger en m├®moire. Quand toutes les op├®rations de lecture et d'├®criture auront ├®t├® effectu├®es, le fichier devra ├¬tre┬Āreferm├®┬Āafin d'enregistrer les ├®ventuelles derni├©res modifications et surtout de lib├®rer la m├®moire occup├®e.
V-A-1. Ouverture d'un fichier▲
On ouvre un fichier en appelant la fonction 3dh de l'interruption 21h. Celle-ci attend comme param├©tre dans DS:DX┬Āl'adresse d'une cha├«ne de caract├©res┬Āqui contient le chemin d'acc├©s au fichier sur un disque, par exemple ŌĆ£C:\MonDoss\MonFic.txtŌĆØ.
Remarque┬Ā: il n'est pas indispensable de mentionner le chemin d'acc├©s complet┬Ā: par d├®faut, le fichier sera cherch├® ├Ā partir du dossier courant.
Remarque importante┬Ā: La cha├«ne doit ├¬tre imp├®rativement suivie de l'octet 00h qui sert ├Ā marquer sa fin.
Il nous faut ├®galement sp├®cifier le┬Āmode d'acc├©s┬Āen ├®crivant dans AL un 0 (si on veut ouvrir le fichier en┬Ālecture seule), un 1 (si on veut l'ouvrir en┬Ā├®criture seule) ou un 2 (lecture┬ĀET┬Ā├®criture).
Si l'interruption ├®choue, le flag CF sera mis ├Ā 1 sans que le fichier soit ouvert. Dans le cas contraire, CF est mis 0 et le registre AX contient un petit nombre entier (par exemple 5) appel├® ┬½┬Āhandle┬Ā┬╗ (ce qui signifie ┬½┬Āpoign├®e┬Ā┬╗) du fichier.┬ĀCe handle repr├®sente le fichier. C'est lui qu'il faudra d├®sormais invoquer pour effectuer des op├®rations de lecture ou d'├®criture, et non pas le chemin d'acc├©s.┬Ā
En effet, les chemins d'acc├©s ne sont donc plus d'aucune utilit├® puisque les fichiers sont ouverts dans la m├®moire vive.
V-A-2. Lecture dans un fichier▲
Une fois le fichier ouvert, on peut le lire avec la fonction 3fh. Il suffit de mentionner le handle dans BX, le nombre d'octets ├Ā lire dans CX, et l'adresse d'un┬Ābuffer┬Ādans DS:DX.┬Ā
Au cas o├╣ vous ne sauriez pas ce qu'est un┬Ābuffer┬Ā(ou┬Ātampon), sachez que c'est simplement une variable (g├®n├®ralement une cha├«ne de caract├©res) destin├®e ├Ā┬Ārecevoir des donn├®es┬Ā(ou ├Ā en fournir). Dans notre cas, le buffer va recevoir les octets lus dans le fichier.
Apr├©s l'appel, AX contient le nombre d'octets qui ont ├®t├® effectivement lus (il peut ├¬tre inf├®rieur ├Ā la taille demand├®e si le fichier n'est pas assez long). En cas de probl├©me, CF sera mis ├Ā 1.
V-A-3. ├ēcriture dans un fichier▲
Pour ├®crire des donn├®es, on proc├©de de m├¬me avec la fonction 40h. Les param├©tres sont les m├¬mes que pour la fonction 3fh. Le┬Ābuffer┬Ācontient cette fois les octets ├Ā┬Ā├®crire. Apr├©s l'appel, le nombre d'octets qui ont ├®t├® effectivement ├®crits est stock├® dans AX (il sera ├¬tre inf├®rieur ├Ā la taille sp├®cifi├®e si le disque est plein).
Les donn├®es sont ├®crites sur le disque dur que le tampon (dans la m├®moire vive) est plein.
V-A-4. Existence d'un pointeur de fichier▲
Une question se pose cependant┬Ā:┬Ā├Ā quel endroit du fichier les donn├®es sont-elles lues (ou ├®crites)┬Ā?
R├®ponse┬Ā: quand un fichier est ouvert, un pointeur sp├®cial pointant vers le d├®but du fichier est cr├®├®. La premi├©re op├®ration de lecture (ou d'├®criture) se fera donc┬Āau d├®but du fichier.┬Ā
Mais entre chaque op├®ration, le pointeur est incr├®ment├® de la taille des donn├®es que l'on a lues (ou ├®crites). La deuxi├©me op├®ration se fera donc sur les octets qui suivent ceux de la premi├©re.
Remarque┬Ā: Il est possible de modifier directement le pointeur de fichier┬Ā: voyez pour cela la fonction 42hŌĆ”
V-A-5. Fermeture d'un fichier▲
Pour terminer, le fichier doit ├¬tre referm├®. Les modifications ├®ventuellement apport├®es et non enregistr├®es seront ├®crites sur le disque, et le┬Āhandle┬Āsera lib├®r├®. C'est la fonction 3eh qui se charge de tout cela. Elle attend simplement le handle du fichier dans BX. Et comme d'habitude, CF vaut 1 apr├©s l'appel si des erreurs ont ├®t├® rencontr├®es.
Remarque┬Ā: Attention lorsque vous laissez le fichier ouvert longtemps afin d'y ajouter progressivement des donn├®es┬Ā! Si le syst├©me plante, vous perdrez les donn├®es qui se trouvent dans le tampon ├Ā ce moment. C'est pourquoi il est conseill├® de forcer r├®guli├©rement l'├®criture sur le disque en refermant le fichier.
V-A-6. Conclusion▲
Le tableau suivant r├®capitule ces diff├®rentes ├®tapes┬Ā:
| Fonction | Description | Param├©tres |
| 3d h | Ouvrir le fichier |
- DS:DX┬Ā: adresse d'une cha├«ne contenant le chemin d'acc├©s┬Ā
- AL┬Ā: mode d'acc├©s |
| 3e h | Fermer le fichier | - BX┬Ā: handle |
| 3f h | Lire le fichier |
- BX┬Ā: handle┬Ā
- CX┬Ā: nombre d'octets┬Ā - DS:DX┬Ā: adresse d'un buffer |
| 40 h | ├ēcrire dans le fichier |
- BX┬Ā: handle┬Ā
- CX┬Ā: nombre d'octets┬Ā - DS:DX┬Ā: adresse d'un buffer |
V-B. LES FONCTIONS DE RECHERCHE DE FICHIERS▲
Pour rechercher un fichier (ou un dossier), on se sert des fonctions 4eh (┬½┬Ā Find First ┬Ā┬╗) et 4fh (┬½┬Ā Find Next ┬Ā┬╗).
Imaginons par exemple que nous voulions chercher dans le dossier courant tous les fichiers qui portent l'extension ŌĆ£ .com ŌĆØ afin de les supprimer. Comment devons-nous nous y prendre┬Ā?
V-B-1. La fonction 4eh▲
La fonction 4eh sert ├Ā d├®finir des crit├©res de recherche et ├Ā trouver le┬Ā premier ┬Āfichier qui correspond ├Ā ces crit├©res (s'il existe).
On doit passer dans DS:DX l'adresse de la cha├«ne de caract├©res qui contient le┬Ā masque de recherche ┬Ā(dans notre exemple, ce masque est ŌĆ£ *.com ŌĆØ). Par d├®faut, les fichiers sont cherch├®s dans le dossier courant. Mais on peut ├®videmment sp├®cifier un autre chemin dans le masque.
Remarque importante ┬Ā: afin que le DOS puisse conna├«tre sa taille, le masque doit imp├®rativement ├¬tre termin├® par l'octet 00h┬Ā!
On ├®crit ├®galement dans CX les attributs des fichiers que l'on d├®sire trouver. Si CX vaut 0, seuls les fichiers ┬½┬Ānormaux┬Ā┬╗ pourront ├¬tre trouv├®s. En fait, chaque bit de CL repr├®sente un attribut, comme le montre le tableau ci-dessous┬Ā:
| Bit | Signification |
| 1 | Lecture seule |
| 2 | Fichier cach├® |
| 3 | Fichier syst├©me |
| 4 | Volume |
| 5 | R├®pertoire |
| 6 | Fichier |
| 7 | (AucuneŌĆ”) |
| 8 | (AucuneŌĆ”) |
Pour demander ├Ā la fonction 4eh de ne pas oublier les fichiers cach├®s, il suffit donc de charger CX avec la valeur 2 (bit num├®ro 2 =┬Ā1). De m├¬me, l'attribut┬Ā 00000111 b (soit 7) nous permettra de trouver les fichiers en lecture seule, les fichiers cach├®s et les fichiers syst├©mes.
Remarque ┬Ā: Ne vous souciez pas trop des bits num├®ro 4 et 6. Laissez-les ├Ā 0.
Une fois que les param├©tres ont ├®t├® ajust├®s, on peut appeler la fonction 4eh.┬ĀSi aucun fichier n'a ├®t├® trouv├®, le flag CF est mis ├Ā 1.┬ĀOn doit donc faire un test sur CF pour savoir si la recherche peut continuer ou si elle doit s'arr├¬ter.┬Ā
Si au contraire la fonction a trouv├® un fichier, les caract├®ristiques de ce fichier (i.e. son nom, sa taille, ses attributsŌĆ”) sont inscrites dans une zone de la m├®moire appel├®e┬ĀDTA┬Ā(┬½┬ĀDisk Transfer Area┬Ā┬╗).
Mais o├╣ se trouve donc cette DTA et ├Ā quoi ressemble-t-elle┬Ā?
R├®ponse ┬Ā: par d├®faut, le DOS place la DTA dans le PSP de votre programme, ├Ā l'offset 80h.
Remarque ┬Ā: il vous est naturellement possible de la d├®placer en faisant appel ├Ā la fonction 1ah.
Voici la structure de la DTA┬Ā:
| Adresse | Description | Taille (octets) |
| 00 h | Lettre du lecteur (0=courant, 1=A, 2=BŌĆ”) sur lequel se trouve le fichier | 1 |
| 01 h | Mod├©le de la recherche | 11 |
| 0C h | R├®serv├® | 9 |
| 15 h | Attributs du fichier | 1 |
| 16 h | Heure du fichier | 2 |
| 18 h | Date du fichier | 2 |
| 1A h | Taille du fichier | 4 |
| 1E h | Nom du fichier avec l'extension | 13 |
Puisque par d├®faut la DTA est situ├®e dans le PSP ├Ā l'offset 80h, le nom du fichier trouv├® est ├®crit ├Ā l'offset 80h + 1eh =┬Ā9eh. De m├¬me, la taille se trouve ├Ā l'offset 9ah, etc.
V-B-2. La fonction 4fh▲
Jusqu'├Ā pr├®sent, nous n'avons trouv├® qu'un seul fichier┬Ā! Pour poursuivre la recherche, appelez la fonction 4fh sans ├®crire aucun param├©tre dans les registres. Les caract├®ristiques de votre recherche ont ├®t├® m├®moris├®es dans la DTA┬Ā: vous n'avez donc pas ├Ā les rappeler. De m├¬me que pour la fonction 4eh, CF est mis ├Ā 1 si aucun nouveau fichier n'a ├®t├® trouv├®. C'est le signe que vous pouvez arr├¬ter votre recherche.
V-B-3. Conclusion▲
R├®sumons-nous┬Ā:
| Fonction | Description | Param├©tres |
| 4e h | Trouver le premier fichier qui correspond aux caract├®ristiques sp├®cifi├®es |
- DS:DX┬Ā: adresse d'une cha├«ne contenant le masque┬Ā
- CX┬Ā: attributs |
| 4f h | Trouver le prochain fichier | Aucun┬Ā! |
├Ć titre d'exemple, ├®crivons ├Ā pr├®sent le programme que nous ├®voquions tout ├Ā l'heure┬Ā: ŌĆ£ trouver tous les fichiers COM du dossier courant et les effacer ŌĆØ.
V-B-4. EXEMPLE DE PROGRAMME▲
V-B-5. Entr├®e bufferis├®e au clavier▲
L'exemple que nous proposons ici fait appel ├Ā une saisie au clavier. Comme nous n'en avons pas encore rencontr├®, ce paragraphe explique bri├©vement comment utiliser les fonctions 0ah et 0ch.
On peut se servir de la fonction 0ah pour lire une cha├«ne de caract├©res au clavier. Le seul param├©tre ├Ā fournir est┬Āl'adresse d'un buffer. Comme il est souvent indispensable d'effacer le buffer avant la lecture, il est pr├®f├®rable de ne pas utiliser la fonction 0ah directement, mais d'appeler la fonction 0ch. En effet, celle-ci commence par┬Āeffacer le buffer, puis┬Āappelle la fonction 0ah┬Ā(ou une fonction voisine dont le num├®ro doit ├¬tre transmis dans AL).
Voici le code ├Ā ├®crire┬Ā:

La seule difficult├® est dans la d├®claration du buffer. Voici comment vous devez vous y prendre si vous consid├®rez que l'utilisateur pourra entrer au plus┬Ān┬Ācaract├©res┬Ā:

Le premier octet de ŌĆ£maChaineŌĆØ doit contenir le nombre d'octets maximal qui pourront ├¬tre entr├®s, plus 1. Pourquoi plus 1┬Ā? Tout simplement parce que le DOS met ├Ā la fin des caract├©res tap├®s le code ASCII 13 (retour chariot).
Pour comprendre la suite de la d├®claration, il faut savoir de quelle mani├©re le DOS transmet les caract├©res qui ont ├®t├® lus. Apr├©s la lecture, le deuxi├©me octet du buffer contiendra le nombre exact d'octets lus (sans compter le 13 final). La cha├«ne proprement dite ne commencera donc qu'au troisi├©me octet. Puisqu'un octet est utilis├® pour donner au DOS le nombre maximal de caract├©res autoris├®s, un autre pour recevoir le nombre de caract├©res lus effectivement, et encore un autre pour recevoir le code ASCII 13, le buffer doit comporter trois octets de plus que la taille maximale de la cha├«ne. C'est pourquoi on ├®crit┬Ā:
maChaine┬Ādb┬Ān+1, ?,┬Ān┬Ādup(?), ?
V-B-6. Le programme▲
Le programme suivant demande ├Ā l'utilisateur d'entrer le nom d'un fichier se trouvant dans le dossier courant puis crypte ce fichier en appliquant un NOT logique sur chaque octet. Naturellement, il n'est pas optimis├® du tout. Ce n'est qu'un exemple┬Ā!

Suggestion┬Ā: quand vous aurez compris ce petit programme, essayez donc de l'am├®liorer┬Ā! Par exemple, il faudrait que l'utilisateur puisse taper le nom du fichier ├Ā crypter directement comme param├©tre du programme (i.e. ŌĆ£CRY MONFICH.EXEŌĆØ). Voyez pour cela la structure du PSP telle que pr├®sent├®e dans la premi├©re partie. De plus, le programme devrait pouvoir trouver automatiquement le nom du fichier d'arriv├®e┬Ā: ce serait le m├¬me que celui du fichier ├Ā crypter, mais avec une extension diff├®rente (par exemple ŌĆ£.cryŌĆØ).┬Ā
Vous pourriez ├®galement ├®tendre les possibilit├®s du logiciel en permettant ├Ā l'utilisateur de saisir non plus un simple nom de fichier, mais un masque complexe avec des chemins d'acc├©s et des caract├©res ŌĆ£jokersŌĆØ comme '*' et '?'. Vous aurez donc besoin des fonctions de recherche 4eh et 4fh. L'utilisateur doit de surcro├«t pouvoir choisir s'il veut crypter un fichier ou bien le d├®crypterŌĆ”
VI. CONCLUSION▲
Voil├Ā. Nous esp├®rons que vous avez compris l'essentiel de ce cours, ├Ā savoir la logique de la programmation en assembleur. Les connaissances que vous avez acquises en lisant la fin du cours devraient vous permettre de mieux saisir les premiers chapitres. C'est pourquoi nous vous invitons ├Ā relire ce tutoriel.
Certaines notions doivent encore vous para├«tre obscures. Maintenant que vous vous ├¬tes familiaris├® avec l'assembleur, commencez par ├®crire et tester quelques petits programmes COM inutiles et tr├©s simples. Vous verrez qu'au bout de quelques essais, tout ce que vous avez lu vous semblera tr├©s concret.
Lorsque vous aurez ├®crit vous-m├¬me quelques tout petits programmes qui fonctionnent, l'assimilation du langage deviendra alors tr├©s rapide, car l'assembleur est un langage tr├©s logique et tr├©s coh├®rent.
Nous vous conseillons d'├®crire une biblioth├©que de petites macros ou proc├®dures qui vous serviront dans tous vos programmes. Par exemple, vous pouvez faire une macro qui affiche un entier ├Ā l'├®cran, ou bien qui convertit une cha├«ne de caract├©res en un nombre entier.
Voici un exemple de macro qui renvoie dans AL le nombre de chiffres d'un entier non sign├® de deux octets pass├® dans AX┬Ā:

N.B. Pensez avant toute chose ├Ā vous munir d'une liste des interruptions du DOS. Vous ne pourrez rien faire si vous n'en avez pas┬Ā!
Bon courage et bonne chance┬Ā!